# 一、注册 handler 流程
# 1. 核心数据结构
# 1.1 gin.Engine
type Engine struct { | |
// 路由组 | |
RouterGroup | |
...... | |
//context 对象池 | |
pool sync.Pool | |
// 方法路由树,共 9 棵路由树,对应 9 中 http 方法。路由树基于压缩前缀树实现 | |
trees methodTrees | |
...... | |
} |
Engine 为 Gin 中构建的 HTTP Handler,其实现了 net/http 包下 Handler interface 的抽象方法:Handler.ServeHTTP,因此可以作为 Handler 注入到 net/http 的 Server 当中
//net/http 包下的 Handler interface | |
type Handler interface { | |
ServeHTTP(ResponseWriter, *Request) | |
} | |
// ServeHTTP conforms to the http.Handler interface. | |
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) { | |
c := engine.pool.Get().(*Context) | |
c.writermem.reset(w) | |
c.Request = req | |
c.reset() | |
engine.handleHTTPRequest(c) | |
engine.pool.Put(c) | |
} |
9 种 http 方法
const ( | |
MethodGet = "GET" | |
MethodHead = "HEAD" | |
MethodPost = "POST" | |
MethodPut = "PUT" | |
MethodPatch = "PATCH" // RFC 5789 | |
MethodDelete = "DELETE" | |
MethodConnect = "CONNECT" | |
MethodOptions = "OPTIONS" | |
MethodTrace = "TRACE" | |
) |
# 1.2 RouteGroup
RouteGroup 是路由组的概念,其中的配置将被从属该路由组的所有路由复用
type RouterGroup struct { | |
Handlers HandlersChain | |
basePath string | |
engine *Engine | |
root bool | |
} |
- Handlers:路由组共同的 handler 处理函数链。组下的节点将凭借 RouteGroup 的公用 handlers 和自己的 handlers,组成最终使用的 handlers 链
- basePath:路由组的基础路径。组下的结点将凭借 RouteGroup 的 basePath 和自己的 path,组成最终的 absolutePath
- engine:指向路由组从属的 Engine
- root:表示路由组是否位于 Engine 的跟结点。当用户基于 RouteGroup.Group 方法创建子路由组后,该标识为 false
# 1.3 HandlersChain
type HandlersChain []HandlerFunc | |
type HandlerFunc func(*Context) |
HandlersChain 是由多个路由处理函数 HandlerFunc 构成的处理函数链。
在使用的时候,会按照索引的先后顺序依次调用 HandlerFunc
# 2. 流程入口
var myMiddleWare = func (ctx *gin.Context) { | |
fmt.Println("my middleware is running....") | |
} | |
func main(){ | |
// 创建一个 gin Engine,本质上是一个 http Handler | |
engine := gin.Default() | |
// 注册中间件 | |
engine.Use(myMiddleWare) | |
// 注册一个 path 为 ping 的处理函数 | |
engine.POST("/ping",func(ctx *gin.Context) { | |
ctx.Writer.Write([]byte("hello pong!")) | |
}) | |
if err := engine.Run(":8080"); err != nil { | |
panic(err) | |
} | |
} |
# 3. 初始化 Engine
gin.Default() -> gin.New()
// gin.Default() | |
func Default(opts ...OptionFunc) *Engine { | |
debugPrintWARNINGDefault() | |
engine := New() | |
engine.Use(Logger(), Recovery()) | |
return engine.With(opts...) | |
} | |
// gin.New() | |
func New(opts ...OptionFunc) *Engine { | |
// 创建一个 gin.Engine 实例 | |
engine := &Engine{ | |
// 创建一个 Engine 的首个 RouteGroup,对应的处理函数链 handlers 为 nil,基础路径 basePath 为 "/",root 标识为 true | |
RouterGroup: RouterGroup{ | |
Handlers: nil, | |
basePath: "/", | |
root: true, | |
}, | |
FuncMap: template.FuncMap{}, | |
RedirectTrailingSlash: true, | |
RedirectFixedPath: false, | |
HandleMethodNotAllowed: false, | |
ForwardedByClientIP: true, | |
RemoteIPHeaders: []string{"X-Forwarded-For", "X-Real-IP"}, | |
TrustedPlatform: defaultPlatform, | |
UseRawPath: false, | |
RemoveExtraSlash: false, | |
UnescapePathValues: true, | |
MaxMultipartMemory: defaultMultipartMemory, | |
trees: make(methodTrees, 0, 9), // 创造 9 棵方法路由树,对应于 9 种 http 方法 | |
delims: render.Delims{Left: ", Right: "}, | |
secureJSONPrefix: "while(1);", | |
trustedProxies: []string{"0.0.0.0/0", "::/0"}, | |
trustedCIDRs: defaultTrustedCIDRs, | |
} | |
engine.RouterGroup.engine = engine | |
//gin.context 对象池 | |
engine.pool.New = func() any { | |
return engine.allocateContext(engine.maxParams) | |
} | |
return engine.With(opts...) | |
} |
# 4. 注册 middleware
通过 engine.Use 方法可以实现中间件的注册,会将注册的 middlewares 添加到 RouteGroup.Handlers 中
后续 RouteGroup 下新注册的 handler 都会在前缀中拼上这部分 group 公共的 handlers
func (engine *Engine) Use(middleware ...HandlerFunc) IRoutes { | |
// 可以注册多个中间件 | |
engine.RouterGroup.Use(middleware...) | |
// ...... | |
return engine | |
} | |
func (group *RouterGroup) Use(middleware ...HandlerFunc) IRoutes { | |
group.Handlers = append(group.Handlers, middleware...) | |
return group.returnObj() | |
} |
# 5. 注册 handler
以 Post 为例:
func (group *RouterGroup) POST(relativePath string, handlers ...HandlerFunc) IRoutes { | |
return group.handle(http.MethodPost, relativePath, handlers) | |
} | |
func (group *RouterGroup) handle(httpMethod, relativePath string, handlers HandlersChain) IRoutes { | |
absolutePath := group.calculateAbsolutePath(relativePath) | |
handlers = group.combineHandlers(handlers) | |
group.engine.addRoute(httpMethod, absolutePath, handlers) | |
return group.returnObj() | |
} |
# 5.1 完整路径拼接
结合 RouteGroup 中的 basePath 和注册时传入的 relativePath,组成 absolutePath
func (group *RouterGroup) calculateAbsolutePath(relativePath string) string { | |
return joinPaths(group.basePath, relativePath) | |
} | |
func joinPaths(absolutePath, relativePath string) string { | |
if relativePath == "" { | |
return absolutePath | |
} | |
finalPath := path.Join(absolutePath, relativePath) | |
if lastChar(relativePath) == '/' && lastChar(finalPath) != '/' { | |
return finalPath + "/" | |
} | |
return finalPath | |
} |
# 5.2 完整 handlers 生成
深拷贝 RouterGroup 中 handlers 和注册传入的 handlers,生成新的 handlers 数组并返回
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain { | |
finalSize := len(group.Handlers) + len(handlers) | |
assert1(finalSize < int(abortIndex), "too many handlers") | |
mergedHandlers := make(HandlersChain, finalSize) | |
copy(mergedHandlers, group.Handlers) | |
copy(mergedHandlers[len(group.Handlers):], handlers) | |
return mergedHandlers | |
} |
# 5.3 注册 handler 到路由树
获取 http method 对应的 methodTree
将 absolutePath 和对应的 handlers 注册到 methodTree 中
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) { | |
assert1(path[0] == '/', "path must begin with '/'") | |
assert1(method != "", "HTTP method can not be empty") | |
assert1(len(handlers) > 0, "there must be at least one handler") | |
debugPrintRoute(method, path, handlers) | |
root := engine.trees.get(method) | |
if root == nil { | |
root = new(node) | |
root.fullPath = "/" | |
engine.trees = append(engine.trees, methodTree{method: method, root: root}) | |
} | |
root.addRoute(path, handlers) | |
// ...... | |
} |
# 二、 启动服务流程
# 1. 流程入口
func main(){ | |
// 创建一个 gin Engine,本质上是一个 http Handler | |
engine := gin.Default() | |
// 一键启动 http 服务 | |
if err := engine.Run(":8089"); err != nil { | |
panic(err) | |
} | |
} |
# 2. 启动服务
底层会将 gin.Engine 本身作为 net/http 包下 Handler interface 的实现类,并调用 http.ListenAndServe 方法启动服务
func (engine *Engine) Run(addr ...string) (err error) { | |
// ...... | |
address := resolveAddress(addr) | |
debugPrint("Listening and serving HTTP on %s\n", address) | |
err = http.ListenAndServe(address, engine.Handler()) | |
return | |
} |
ListenAndServe 方法本身会基于主动轮询 + IO 多路复用的方式运行,因此程序在正常运行时,会始终阻塞于 Engine.Run 方法,不会返回。
func ListenAndServe(addr string, handler Handler) error { | |
server := &Server{Addr: addr, Handler: handler} | |
return server.ListenAndServe() | |
} | |
func (s *Server) ListenAndServe() error { | |
if s.shuttingDown() { | |
return ErrServerClosed | |
} | |
addr := s.Addr | |
if addr == "" { | |
addr = ":http" | |
} | |
ln, err := net.Listen("tcp", addr) | |
if err != nil { | |
return err | |
} | |
return s.Serve(ln) | |
} | |
func (s *Server) Serve(l net.Listener) error { | |
// ...... | |
ctx := context.WithValue(baseCtx, ServerContextKey, s) | |
for { | |
rw, err := l.Accept() | |
if err != nil { | |
if s.shuttingDown() { | |
return ErrServerClosed | |
} | |
if ne, ok := err.(net.Error); ok && ne.Temporary() { | |
if tempDelay == 0 { | |
tempDelay = 5 * time.Millisecond | |
} else { | |
tempDelay *= 2 | |
} | |
if max := 1 * time.Second; tempDelay > max { | |
tempDelay = max | |
} | |
s.logf("http: Accept error: %v; retrying in %v", err, tempDelay) | |
time.Sleep(tempDelay) | |
continue | |
} | |
return err | |
} | |
connCtx := ctx | |
if cc := s.ConnContext; cc != nil { | |
connCtx = cc(connCtx, rw) | |
if connCtx == nil { | |
panic("ConnContext returned nil") | |
} | |
} | |
tempDelay = 0 | |
c := s.newConn(rw) | |
c.setState(c.rwc, StateNew, runHooks) // before Serve can return | |
go c.serve(connCtx) | |
} | |
} |
# 3. 处理请求
在服务端接收到 http 请求时,会通过 Handler.ServeHTTP 方法进行处理。而此处的 Handler 正式 gin.Engine,其处理请求的核心步骤如下:
- 对每笔 http 请求,会为其分配一个 gin.Context,在 handlers 链路中持续向下传递
- 调用 Engine.handleHTTPRequest 方法,从路由树中获取 handlers 链,然后遍历调用
- 处理完 http 请求后,会将 gin.Context 进行回收。整个回收复用的流程基于对象池管理
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) { | |
// 从对象池中获取一个 context | |
c := engine.pool.Get().(*Context) | |
// 初始化 context | |
c.writermem.reset(w) | |
c.Request = req | |
c.reset() | |
// 处理 http 请求 | |
engine.handleHTTPRequest(c) | |
// 把 context 放回对象池 | |
engine.pool.Put(c) | |
} |
func (engine *Engine) handleHTTPRequest(c *Context) { | |
httpMethod := c.Request.Method | |
rPath := c.Request.URL.Path | |
unescape := false | |
if engine.UseRawPath && len(c.Request.URL.RawPath) > 0 { | |
rPath = c.Request.URL.RawPath | |
unescape = engine.UnescapePathValues | |
} | |
if engine.RemoveExtraSlash { | |
rPath = cleanPath(rPath) | |
} | |
t := engine.trees | |
for i, tl := 0, len(t); i < tl; i++ { | |
// 获取对应的方法树 | |
if t[i].method != httpMethod { | |
continue | |
} | |
root := t[i].root | |
// 从路由树中寻找路由 | |
value := root.getValue(rPath, c.params, c.skippedNodes, unescape) | |
if value.params != nil { | |
c.Params = *value.params | |
} | |
if value.handlers != nil { | |
c.handlers = value.handlers | |
c.fullPath = value.fullPath | |
c.Next() | |
c.writermem.WriteHeaderNow() | |
return | |
} | |
if httpMethod != http.MethodConnect && rPath != "/" { | |
if value.tsr && engine.RedirectTrailingSlash { | |
redirectTrailingSlash(c) | |
return | |
} | |
if engine.RedirectFixedPath && redirectFixedPath(c, root, engine.RedirectFixedPath) { | |
return | |
} | |
} | |
break | |
} | |
if engine.HandleMethodNotAllowed { | |
allowed := make([]string, 0, len(t)-1) | |
for _, tree := range engine.trees { | |
if tree.method == httpMethod { | |
continue | |
} | |
if value := tree.root.getValue(rPath, nil, c.skippedNodes, unescape); value.handlers != nil { | |
allowed = append(allowed, tree.method) | |
} | |
} | |
if len(allowed) > 0 { | |
c.handlers = engine.allNoMethod | |
c.writermem.Header().Set("Allow", strings.Join(allowed, ", ")) | |
serveError(c, http.StatusMethodNotAllowed, default405Body) | |
return | |
} | |
} | |
c.handlers = engine.allNoRoute | |
serveError(c, http.StatusNotFound, default404Body) | |
} |
# 三、Gin 路由树
# 1. 策略与原理
# 1.1 前缀树
- 除根结点之外,每个结点对应一个字符
- 从根结点到某一个结点,路径上经过的字符串连起来,即为该结点对应的字符串
- 尽可能复用公共前缀,如务必要不分配新的结点
# 1.2 压缩前缀树
对前缀树进行改良,主要在于空间的节省,核心体现在:
倘若某个子结点是其父结点的唯一孩子,则与父结点进行合并
# 1.3 为什么使用压缩前缀树
相对于使用 map,以 path 为 key,handlers 为 value 进行映射关联,使用前缀树的原因在于:
- path 匹配时不是完全精确匹配,比如末尾‘/’符号的增减、全匹配符号‘*’的处理等,map 无法胜任
- 路由的数量相对有限,对应数量级下 map 的性能优势体现不明显,在小数据量的前提下,map 性能甚至要弱于前缀树
- path 传通过后出纳号存在基于分组分类的公共前缀,适合使用前缀树进行管理,可以节省存储空间
| 维度 | map[string] |
压缩前缀树 |
|---|---|---|
| 匹配速度 | O (1),但只能完全匹配 | 近似 O (n)(路径段数),但支持模式 |
| 内存占用 | 高(冗余字符串很多) | 更低(公共前缀合并) |
| 动态参数支持 | 不支持 | 支持 |
| 通配符支持 | 不支持 | 支持 |
| 动态路由支持 | 不支持 | 支持 |
# 1.4 补偿策略
在组装路由树时,会将注册路由句柄数量更多的 child node 摆放在 children 数组更靠前的位置
这是应为某个链路注册的 handlers 句柄数量越多,一次匹配操作所需要花费的时间就越长,被匹配命中的概率就越大,因此应该被优先处理
# 2. 核心数据结构
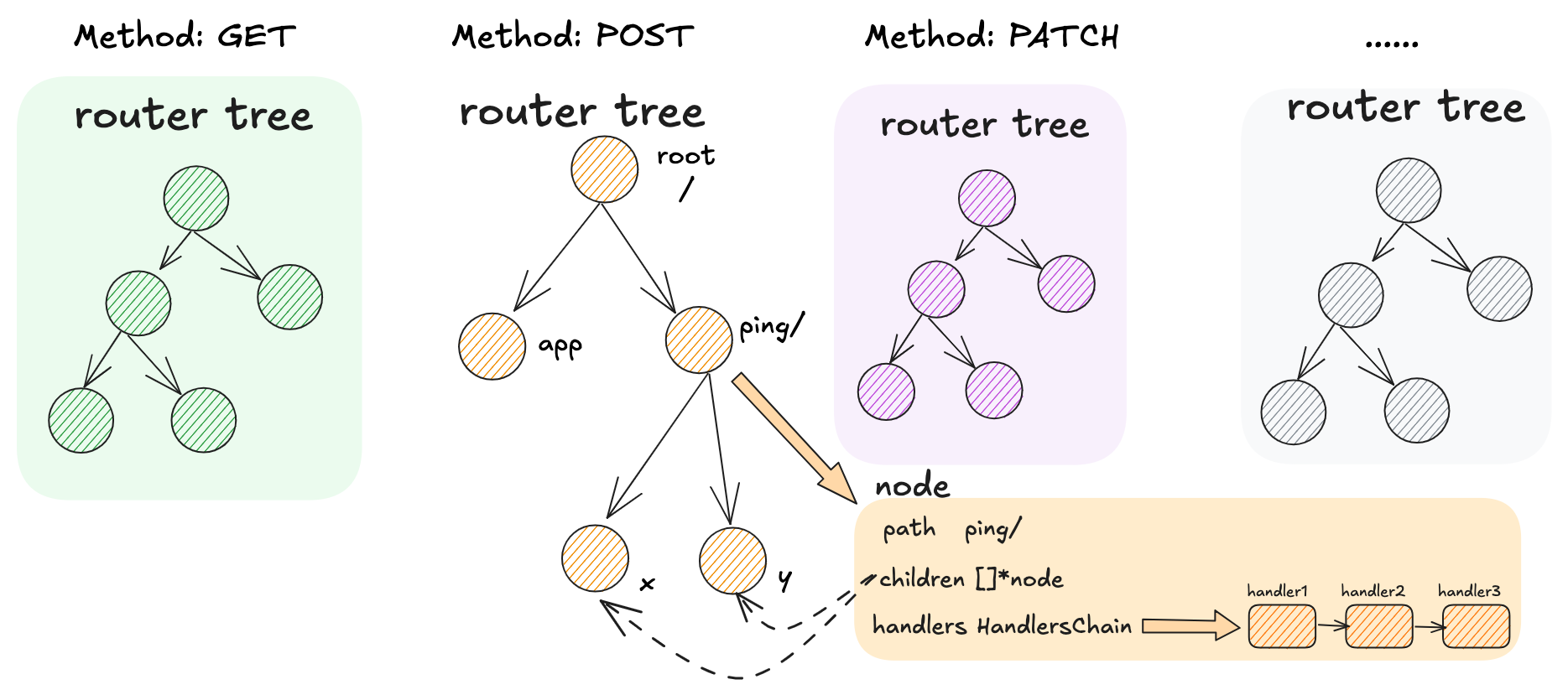
路由树的数据结构,对应于 9 种 http method,共有 9 中 methodTree。
每棵 methodTree 会通过 root 指向 radix tree 的根结点
type methodTree struct { | |
method string | |
root *node //radix tree 中的结点 | |
} | |
type node struct { | |
// 结点的相对路径,拼接上 RouterGroup 中的 basePath 作为前缀后才能拿到完整的路由 path | |
path string | |
// 由各个结点 path 首字母组成的字符串,子节点顺序会按照途径的路由数量 priority 进行排序 | |
indices string | |
wildChild bool | |
nType nodeType | |
// 途径本结点的路由数量,反映出本结点在父结点中被检索由的优先级 | |
priority uint32 | |
// 子节点列表 | |
children []*node // child nodes, at most 1 :param style node at the end of the array | |
// 当前节点对应的处理函数链 | |
handlers HandlersChain | |
//path 拼接上前缀后的完整路径 | |
fullPath string | |
} |
# 3. 注册到路由树
将一组 path + handlers 添加到 radix tree 的详细过程
func (engine *Engine) addRoute(method, path string, handlers HandlersChain) { | |
assert1(path[0] == '/', "path must begin with '/'") | |
assert1(method != "", "HTTP method can not be empty") | |
assert1(len(handlers) > 0, "there must be at least one handler") | |
debugPrintRoute(method, path, handlers) | |
root := engine.trees.get(method) | |
if root == nil { | |
root = new(node) | |
root.fullPath = "/" | |
engine.trees = append(engine.trees, methodTree{method: method, root: root}) | |
} | |
root.addRoute(path, handlers) | |
if paramsCount := countParams(path); paramsCount > engine.maxParams { | |
engine.maxParams = paramsCount | |
} | |
if sectionsCount := countSections(path); sectionsCount > engine.maxSections { | |
engine.maxSections = sectionsCount | |
} | |
} |
func (n *node) addRoute(path string, handlers HandlersChain) { | |
fullPath := path | |
// 每有一个新路由经过此节点,priority 都要加 1 | |
n.priority++ | |
// Empty tree | |
// 加入当前节点为 root 且未注册过子节点,则直接插入路由并返回 | |
if len(n.path) == 0 && len(n.children) == 0 { | |
n.insertChild(path, fullPath, handlers) | |
n.nType = root | |
return | |
} | |
parentFullPathIndex := 0 | |
// 外层 for 循环断点 | |
walk: | |
for { | |
// Find the longest common prefix. | |
// This also implies that the common prefix contains no ':' or '*' | |
// since the existing key can't contain those chars. | |
// 获取 node.path 和 待插入 path 的最长公共前缀长度 | |
i := longestCommonPrefix(path, n.path) | |
// Split edge | |
// 倘若最长公共前缀长度小于 node.path 的长度,代表 node 需要分裂 | |
if i < len(n.path) { | |
// 原结点分裂的后半部分 | |
child := node{ | |
path: n.path[i:], | |
wildChild: n.wildChild, | |
nType: static, | |
indices: n.indices, | |
children: n.children, | |
handlers: n.handlers, | |
priority: n.priority - 1, | |
fullPath: n.fullPath, | |
} | |
n.children = []*node{&child} | |
// []byte for proper unicode char conversion, see #65 | |
n.indices = bytesconv.BytesToString([]byte{n.path[i]}) | |
n.path = path[:i] | |
n.handlers = nil | |
n.wildChild = false | |
n.fullPath = fullPath[:parentFullPathIndex+i] | |
} | |
// Make new node a child of this node | |
// 最长公共前缀长度小于 path,正如 se 之于 see | |
if i < len(path) { | |
//path see 扣除公共前缀 se,剩余 e | |
path = path[i:] | |
c := path[0] | |
// '/' after param | |
if n.nType == param && c == '/' && len(n.children) == 1 { | |
parentFullPathIndex += len(n.path) | |
n = n.children[0] | |
n.priority++ | |
continue walk | |
} | |
// Check if a child with the next path byte exists | |
// 根据 node.indices,辅助判断,其子节点中是否与当前 path 还存在公共前缀 | |
for i, max := 0, len(n.indices); i < max; i++ { | |
// 让若 node 子结点还与 path 有公共前缀,则零 node = child,并调到外层 for 循环 walk 位置开始新一轮处理 | |
if c == n.indices[i] { | |
parentFullPathIndex += len(n.path) | |
i = n.incrementChildPrio(i) | |
n = n.children[i] | |
continue walk | |
} | |
} | |
// Otherwise insert it | |
// | |
if c != ':' && c != '*' && n.nType != catchAll { | |
//node 已经不存在和 path 有公共前缀的子结点了,则需要将 path 包装成一个新 child node 进行插入 | |
//node 的 indices 新增 path 的首字母 | |
n.indices += bytesconv.BytesToString([]byte{c}) | |
// 把新路由包装成一个 child node,对应的 path 和 handlers 会在 node.insertChild 中赋值 | |
child := &node{ | |
fullPath: fullPath, | |
} | |
// 新 child node appen 到 node.children 数组中 | |
n.addChild(child) | |
n.incrementChildPrio(len(n.indices) - 1) | |
// 令 node 指向新插入的 child,并在 node.insertChild 方法中进行 path 和 handlers 的赋值操作 | |
n = child | |
} else if n.wildChild { | |
// inserting a wildcard node, need to check if it conflicts with the existing wildcard | |
n = n.children[len(n.children)-1] | |
n.priority++ | |
// Check if the wildcard matches | |
if len(path) >= len(n.path) && n.path == path[:len(n.path)] && | |
// Adding a child to a catchAll is not possible | |
n.nType != catchAll && | |
// Check for longer wildcard, e.g. :name and :names | |
(len(n.path) >= len(path) || path[len(n.path)] == '/') { | |
continue walk | |
} | |
// Wildcard conflict | |
pathSeg := path | |
if n.nType != catchAll { | |
pathSeg = strings.SplitN(pathSeg, "/", 2)[0] | |
} | |
prefix := fullPath[:strings.Index(fullPath, pathSeg)] + n.path | |
panic("'" + pathSeg + | |
"' in new path '" + fullPath + | |
"' conflicts with existing wildcard '" + n.path + | |
"' in existing prefix '" + prefix + | |
"'") | |
} | |
n.insertChild(path, fullPath, handlers) | |
return | |
} | |
// Otherwise add handle to current node | |
//path 恰好是其与 node.path 的公共前缀,则直接复制 handlers 即可 | |
// 其 handlers 不能为空 | |
if n.handlers != nil { | |
panic("handlers are already registered for path '" + fullPath + "'") | |
} | |
n.handlers = handlers | |
n.fullPath = fullPath | |
return | |
} | |
} |
# 4. 检索路由树
从路由树中匹配 path 对应 handler 的详细过程
type nodeValue struct { | |
handlers HandlersChain // 处理函数链 | |
params *Params | |
tsr bool | |
fullPath string | |
} |
// 从路由树中获取 path 对应的 handlers | |
func (n *node) getValue(path string, params *Params, skippedNodes *[]skippedNode, unescape bool) (value nodeValue) { | |
var globalParamsCount int16 | |
// 外层 for 循环断点 | |
walk: // Outer loop for walking the tree | |
for { | |
prefix := n.path | |
// 带匹配的 path 长度 大于 node.path | |
if len(path) > len(prefix) { | |
//node.path 长度 < path, 且前缀匹配上 | |
if path[:len(prefix)] == prefix { | |
//path 取后半部分 | |
path = path[len(prefix):] | |
// Try all the non-wildcard children first by matching the indices | |
// 遍历当前 node.indices,找到能和 path 后半部分匹配的 child node | |
idxc := path[0] | |
for i, c := range []byte(n.indices) { | |
// 找到首字母匹配的 child node | |
if c == idxc { | |
// strings.HasPrefix(n.children[len(n.children)-1].path, ":") == n.wildChild | |
if n.wildChild { | |
index := len(*skippedNodes) | |
*skippedNodes = (*skippedNodes)[:index+1] | |
(*skippedNodes)[index] = skippedNode{ | |
path: prefix + path, | |
node: &node{ | |
path: n.path, | |
wildChild: n.wildChild, | |
nType: n.nType, | |
priority: n.priority, | |
children: n.children, | |
handlers: n.handlers, | |
fullPath: n.fullPath, | |
}, | |
paramsCount: globalParamsCount, | |
} | |
} | |
// 将 n 指向 child node,调到 walk 断点开始下一轮处理 | |
n = n.children[i] | |
continue walk | |
} | |
} | |
if !n.wildChild { | |
// If the path at the end of the loop is not equal to '/' and the current node has no child nodes | |
// the current node needs to roll back to last valid skippedNode | |
if path != "/" { | |
for length := len(*skippedNodes); length > 0; length-- { | |
skippedNode := (*skippedNodes)[length-1] | |
*skippedNodes = (*skippedNodes)[:length-1] | |
if strings.HasSuffix(skippedNode.path, path) { | |
path = skippedNode.path | |
n = skippedNode.node | |
if value.params != nil { | |
*value.params = (*value.params)[:skippedNode.paramsCount] | |
} | |
globalParamsCount = skippedNode.paramsCount | |
continue walk | |
} | |
} | |
} | |
// Nothing found. | |
// We can recommend to redirect to the same URL without a | |
// trailing slash if a leaf exists for that path. | |
value.tsr = path == "/" && n.handlers != nil | |
return value | |
} | |
// Handle wildcard child, which is always at the end of the array | |
n = n.children[len(n.children)-1] | |
globalParamsCount++ | |
switch n.nType { | |
case param: | |
// fix truncate the parameter | |
// tree_test.go line: 204 | |
// Find param end (either '/' or path end) | |
end := 0 | |
for end < len(path) && path[end] != '/' { | |
end++ | |
} | |
// Save param value | |
if params != nil { | |
// Preallocate capacity if necessary | |
if cap(*params) < int(globalParamsCount) { | |
newParams := make(Params, len(*params), globalParamsCount) | |
copy(newParams, *params) | |
*params = newParams | |
} | |
if value.params == nil { | |
value.params = params | |
} | |
// Expand slice within preallocated capacity | |
i := len(*value.params) | |
*value.params = (*value.params)[:i+1] | |
val := path[:end] | |
if unescape { | |
if v, err := url.QueryUnescape(val); err == nil { | |
val = v | |
} | |
} | |
(*value.params)[i] = Param{ | |
Key: n.path[1:], | |
Value: val, | |
} | |
} | |
// we need to go deeper! | |
if end < len(path) { | |
if len(n.children) > 0 { | |
path = path[end:] | |
n = n.children[0] | |
continue walk | |
} | |
// ... but we can't | |
value.tsr = len(path) == end+1 | |
return value | |
} | |
if value.handlers = n.handlers; value.handlers != nil { | |
value.fullPath = n.fullPath | |
return value | |
} | |
if len(n.children) == 1 { | |
// No handle found. Check if a handle for this path + a | |
// trailing slash exists for TSR recommendation | |
n = n.children[0] | |
value.tsr = (n.path == "/" && n.handlers != nil) || (n.path == "" && n.indices == "/") | |
} | |
return value | |
case catchAll: | |
// Save param value | |
if params != nil { | |
// Preallocate capacity if necessary | |
if cap(*params) < int(globalParamsCount) { | |
newParams := make(Params, len(*params), globalParamsCount) | |
copy(newParams, *params) | |
*params = newParams | |
} | |
if value.params == nil { | |
value.params = params | |
} | |
// Expand slice within preallocated capacity | |
i := len(*value.params) | |
*value.params = (*value.params)[:i+1] | |
val := path | |
if unescape { | |
if v, err := url.QueryUnescape(path); err == nil { | |
val = v | |
} | |
} | |
(*value.params)[i] = Param{ | |
Key: n.path[2:], | |
Value: val, | |
} | |
} | |
value.handlers = n.handlers | |
value.fullPath = n.fullPath | |
return value | |
default: | |
panic("invalid node type") | |
} | |
} | |
} | |
// 倘若 path 正好等于 node.path,说明已经找到目标 | |
if path == prefix { | |
// If the current path does not equal '/' and the node does not have a registered handle and the most recently matched node has a child node | |
// the current node needs to roll back to last valid skippedNode | |
if n.handlers == nil && path != "/" { | |
for length := len(*skippedNodes); length > 0; length-- { | |
skippedNode := (*skippedNodes)[length-1] | |
*skippedNodes = (*skippedNodes)[:length-1] | |
if strings.HasSuffix(skippedNode.path, path) { | |
path = skippedNode.path | |
n = skippedNode.node | |
if value.params != nil { | |
*value.params = (*value.params)[:skippedNode.paramsCount] | |
} | |
globalParamsCount = skippedNode.paramsCount | |
continue walk | |
} | |
} | |
// n = latestNode.children[len(latestNode.children)-1] | |
} | |
// We should have reached the node containing the handle. | |
// Check if this node has a handle registered. | |
// 取出对应的 handlers 进行返回 | |
if value.handlers = n.handlers; value.handlers != nil { | |
value.fullPath = n.fullPath | |
return value | |
} | |
// If there is no handle for this route, but this route has a | |
// wildcard child, there must be a handle for this path with an | |
// additional trailing slash | |
if path == "/" && n.wildChild && n.nType != root { | |
value.tsr = true | |
return value | |
} | |
if path == "/" && n.nType == static { | |
value.tsr = true | |
return value | |
} | |
// No handle found. Check if a handle for this path + a | |
// trailing slash exists for trailing slash recommendation | |
for i, c := range []byte(n.indices) { | |
if c == '/' { | |
n = n.children[i] | |
value.tsr = (len(n.path) == 1 && n.handlers != nil) || | |
(n.nType == catchAll && n.children[0].handlers != nil) | |
return value | |
} | |
} | |
return value | |
} | |
// Nothing found. We can recommend to redirect to the same URL with an | |
// extra trailing slash if a leaf exists for that path | |
value.tsr = path == "/" || | |
(len(prefix) == len(path)+1 && prefix[len(path)] == '/' && | |
path == prefix[:len(prefix)-1] && n.handlers != nil) | |
// roll back to last valid skippedNode | |
if !value.tsr && path != "/" { | |
for length := len(*skippedNodes); length > 0; length-- { | |
skippedNode := (*skippedNodes)[length-1] | |
*skippedNodes = (*skippedNodes)[:length-1] | |
if strings.HasSuffix(skippedNode.path, path) { | |
path = skippedNode.path | |
n = skippedNode.node | |
if value.params != nil { | |
*value.params = (*value.params)[:skippedNode.paramsCount] | |
} | |
globalParamsCount = skippedNode.paramsCount | |
continue walk | |
} | |
} | |
} | |
return value | |
} | |
} |
# 四、gin.Context
# 1. 核心数据结构
gin.Context 的定位是位于一次 https 请求,贯穿于整条 handlersChain 调用链路的上下文
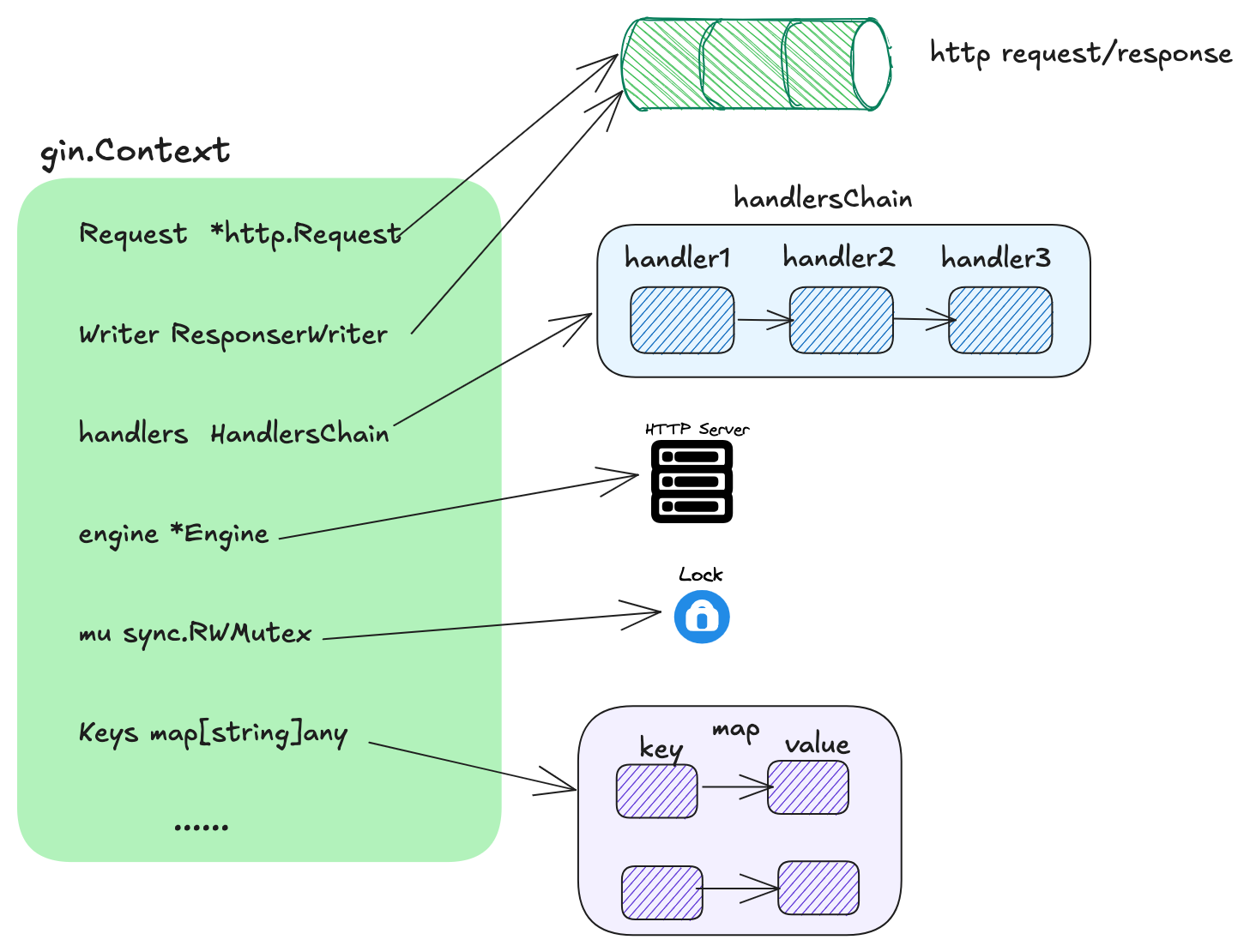
type Context struct { | |
writermem responseWriter | |
//http 请求和相应的 reader、Writer 入口 | |
Request *http.Request | |
Writer ResponseWriter | |
Params Params | |
// 本次 https 请求对应的处理函数链 | |
handlers HandlersChain | |
// 当亲的处理进度,即处理链路处于函数链的索引位置 | |
index int8 | |
fullPath string | |
// Engine 的指针 | |
engine *Engine | |
params *Params | |
skippedNodes *[]skippedNode | |
// 用于保护 map 的读写互斥锁 | |
mu sync.RWMutex | |
// 缓存 handlers 链上共享数据的 map | |
Keys map[string]any | |
// ...... | |
} |
# 2. 复用策略
gin.Context 作为处理 http 请求的通用数据结构,不可避免的会被频繁创建和销毁。为了缓解 GC 压力,gin 中采用对象池 sync.Pool 进行 Context 的缓存复用,处理流程如下:
- http 请求到达时,从 pool 中获取 Context,倘若池子已空,通过 pool.New 方法构造新的 Context 补上空缺
- http 请求处理完成后,将 Context 放回 pool 中,用以后续复用
Sync.Pool 并不是真正意义上的缓存,将其称为回收站或许更加合适,放如其中的数据在逻辑意义上都是已经被删除的,但在物理意义上数据仍然存在,这些数据可以存活两轮 GC 的时间,在此期间倘若有被获取的需求,则可以被重新服用。
func New(opts ...OptionFunc) *Engine { | |
// ...... | |
engine.pool.New = func() any { | |
return engine.allocateContext(engine.maxParams) | |
} | |
return engine.With(opts...) | |
} |
func (engine *Engine) allocateContext(maxParams uint16) *Context { | |
v := make(Params, 0, maxParams) | |
skippedNodes := make([]skippedNode, 0, engine.maxSections) | |
return &Context{engine: engine, params: &v, skippedNodes: &skippedNodes} | |
} |
# 3. 分配与回收时机
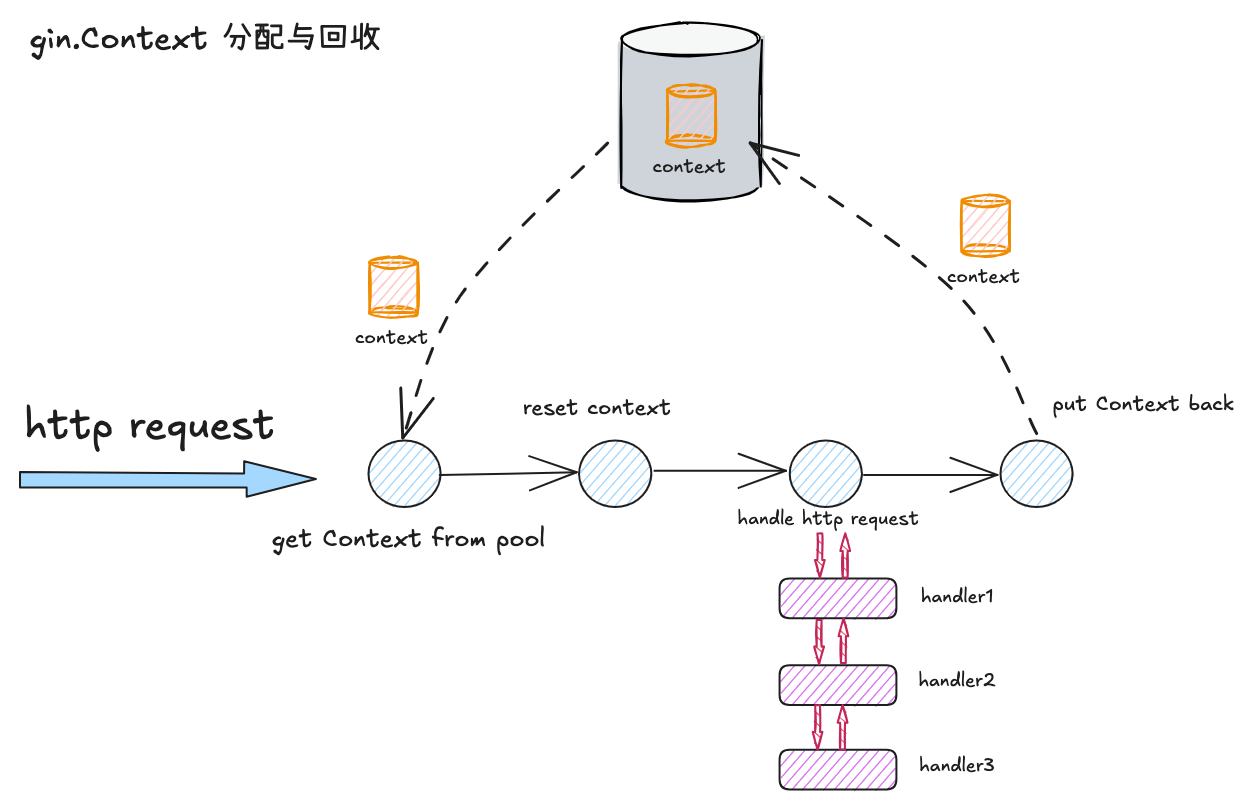
gin.Context 分配与回收的实际是在 gin.Engine 处理 http 请求的前后,位于 Engine.ServeHTTP 方法当中:
- 从池中获取 Context
- 重置 Context 的内容,使其称为一个空白的上下文
- 调用 Engine.handleHTTPRequest 方法处理 http 请求
- 请求处理完成后,将 context 放回池中
func (engine *Engine) ServeHTTP(w http.ResponseWriter, req *http.Request) { | |
// 从对象池中获取一个 context | |
c := engine.pool.Get().(*Context) | |
// 重置、初始化 context | |
c.writermem.reset(w) | |
c.Request = req | |
c.reset() | |
// 处理 http 请求 | |
engine.handleHTTPRequest(c) | |
// 将 context 放回对象池 | |
engine.pool.Put(c) | |
} |
# 4. 使用时机
# 4.1 handlesChain 入口
在 Engine.HandleHTTPRequest 方法处理请求时,会通过 path 从 methodTree 中获取到对应的 handlers 链,然后将 handlers 注入到 Context.handlers 中,然后启动 Context.Next 方法开启 handlers 链的遍历调用流程
func (engine *Engine) handleHTTPRequest(c *Context) { | |
// ...... | |
t := engine.trees | |
for i, tl := 0, len(t); i < tl; i++ { | |
if t[i].method != httpMethod { | |
continue | |
} | |
root := t[i].root | |
// Find route in tree | |
value := root.getValue(rPath, c.params, c.skippedNodes, unescape) | |
if value.params != nil { | |
c.Params = *value.params | |
} | |
if value.handlers != nil { | |
c.handlers = value.handlers | |
c.fullPath = value.fullPath | |
c.Next() | |
c.writermem.WriteHeaderNow() | |
return | |
} | |
// ...... | |
} |
# 4. 2 handlersChain 遍历调用
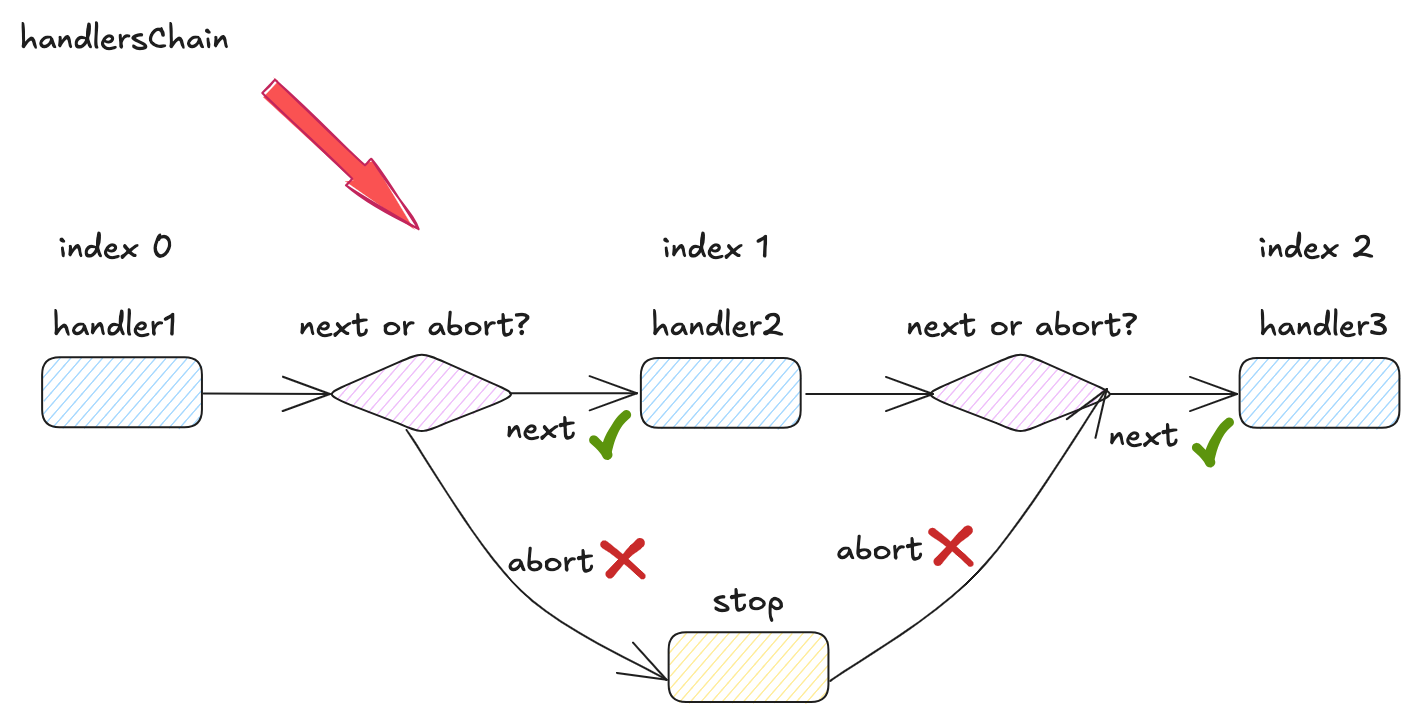
推进 handlers 链调用进度的方法正式 Context.Next. 以 Context.index 为索引,通过 for 循环一次调用 handlers 链中的 handler.
func (c *Context) Next() { | |
c.index++ | |
for c.index < int8(len(c.handlers)) { | |
c.handlers[c.index](c) | |
c.index++ | |
} | |
} |
由于 Context 本身会暴露于调用链路中,因此用户可以在某个 handler 中通过 Context.Next 方式来打断当前 handler 的执行流程,提前进入下一个 handler 的处理中。
由于此时本质上是一个方法压栈调用的行为,因此后置位 handlers 链全部处理完成后,最终会回到压栈前的位置,执行当前 handler 剩余部分的代码逻辑
用户可以在某个 handler 中,于调用 Context.Next 方法的前后分别声明前处理逻辑和后处理逻辑,这里的 “前” 和 “后” 相对的是后置位的所有 handler 而言.
func myHandleFunc(c *gin.Context){ | |
// 前处理 | |
preHandle() | |
c.Next() | |
// 后处理 | |
postHandle() | |
} |
用户可以在某个 handler 中通过 Context.Abort 方法实现 handlers 链路的提前熔断
其实现原理是将 Context.index 设置为一个过载值 63,导致 Next 流程终止。这是应为 handlers 链的长度必须小于 63,否则在注册时就会直接 panic。因此在 Context.Next 方法中,一旦 index 被设为 63,则必然大于整条 handlers 链的长度,for 循环便会提前终止。
const abortIndex int8 = 63 | |
func (c *Context) Abort() { | |
c.index = abortIndex | |
} |
此外,还可以通过 Context.IsAbort 方法检测当前 handlerChain 是否处于正常调用,还是已经被熔断。
func (c *Context) IsAborted() bool { | |
return c.index >= abortIndex | |
} |
注册 handlers,倘若 handlers 链长度达到 63,则会 panic
func (group *RouterGroup) combineHandlers(handlers HandlersChain) HandlersChain { | |
finalSize := len(group.Handlers) + len(handlers) | |
// 断言 handlers 链长度必须小于 63 | |
assert1(finalSize < int(abortIndex), "too many handlers") | |
// ... | |
} |
# 4.3 共享数据存取
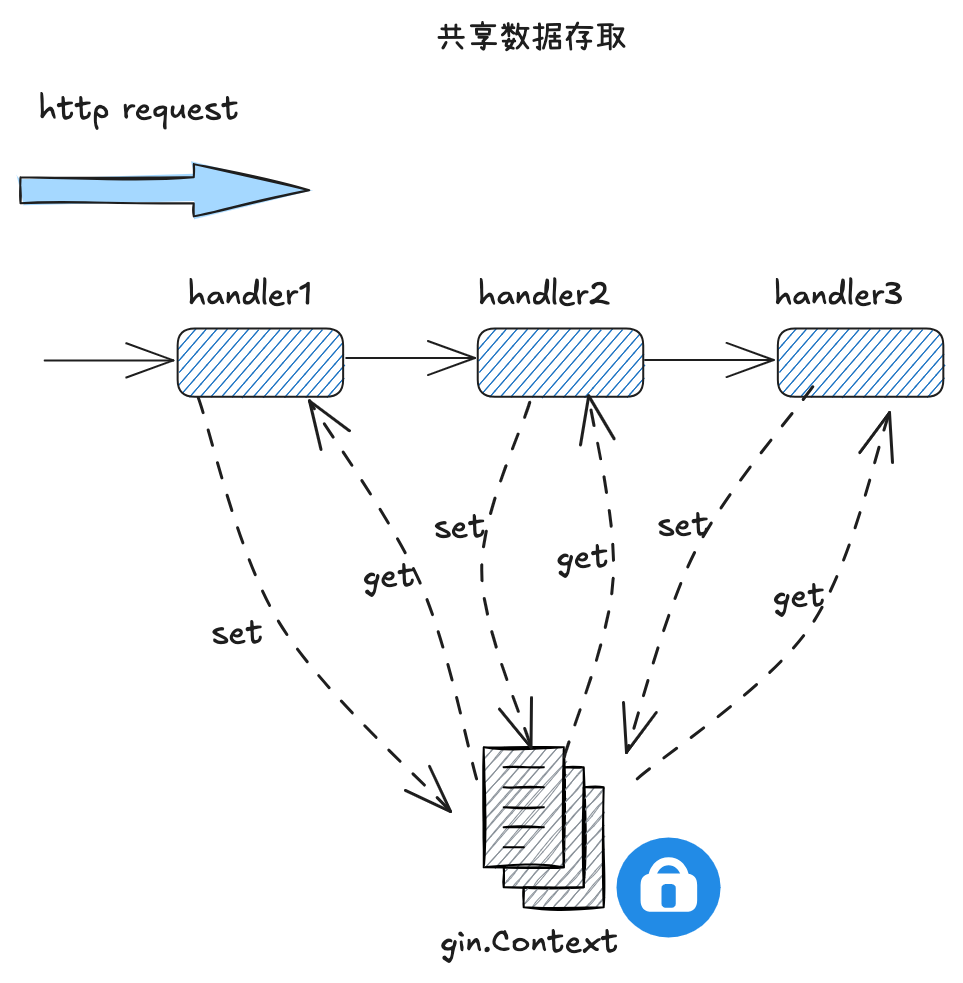
gin.Context 作为 handlers 链的上下文,还提供对外暴露的 Get 和 Set 接口,向用户提供了共享数据的存取服务,相关操作都在读写锁的保护之下,能保证并发安全。
type Context struct { | |
// ... | |
// 读写锁,保证并发安全 | |
mu sync.RWMutex | |
//key value 对存储 map | |
Keys map[string]any | |
} | |
func (c *Context) Get(key string) (value any, exists bool) { | |
c.mu.RLock() | |
defer c.mu.RUnlock() | |
value, exists = c.Keys[key] | |
return | |
} | |
func (c *Context) Set(key string, value any) { | |
c.mu.Lock() | |
defer c.mu.Unlock() | |
if c.Keys == nil { | |
c.Keys = make(map[string]any) | |
} | |
c.Keys[key] = value | |
} |
# 五、总结
- gin 将 Engine 作为 http.Handler 的实现类进行注入,从而融入 Golang net/http 标准库的框架之内
- gin 中基于 handler 链的方式实现中间件和处理函数的协调使用
- gin 中基于压缩前缀树的方式作为路由树的数据结构,对应于 9 中 http 公有 9 棵树
- gin 中基于 gin.Context 作为一次 http 请求贯穿整条 handler Chain 的核心数据结构
- gin.Context 是一种会被频繁创建销毁的资源对象,因此使用对象池 sync.Pool 进行缓存复用