# 1. golang-GMP 概述 🚀
# 什么是 GMP? 🤔
GMP 是 Go 语言运行时 (runtime) 的调度器,它负责将 goroutine 调度到操作系统线程上执行。这个调度器是 Go 语言实现高并发的重要基石!

{}")
# GMP 模型的核心组件 🎯
# 1. G (Goroutine) 🏃♂️
- 轻量级的用户态线程
- 包含执行栈、调度信息、等待队列等
- 初始栈大小只有 2KB,但可以动态扩容
- 由 Go 程序通过
go关键字创建 - 每个 G 都有自己的执行上下文和栈空间
- 状态包括:_Gidle、_Grunnable、_Grunning、_Gsyscall、_Gwaiting、_Gdead
- 可以被抢占,支持协作式调度
# 2. M (Machine) ⚙️
- 代表操作系统线程
- 由操作系统调度
- 每个 M 都有一个特殊的 G0(调度协程)
- 数量由
GOMAXPROCS环境变量决定 - M0 是启动程序后的编号为 0 的线程,负责执行初始化操作和启动第一个 G
- M0 在全局变量 runtime.m0 中,不需要在 heap 上分配
- M0 负责执行初始化操作和启动第一个 G(main goroutine)
- M0 的运行目标始终在 g0 和 g 之间进行切换,-- 当运行 g0 时执行的是 m 的调度流程,负责寻找合适的 G 来运行,-- 当运行 g 时,执行的是 M 获取到的 G,即用户代码
- M0 还可以负责执行垃圾回收等操作
# 3. P (Processor) 🎮
- 调度上下文,可以看作一个 "处理器"
- 维护一个本地 G 队列
- 数量通常等于 CPU 核心数
- 负责将 G 调度到 M 上执行
- P0 是启动程序后的编号为 0 的 P,负责执行 main goroutine
- 每个 P 都有一个本地队列,用于存储等待执行的 G
- P 的数量可以通过 GOMAXPROCS 环境变量或 runtime.GOMAXPROCS () 函数设置
# GMP 的工作流程 🔄
-
创建 Goroutine 🆕
- 程序通过
go关键字创建新的 G - G 会被放入 P 的本地队列或全局队列
- 如果本地队列已满,会放入全局队列
- 创建 G 时会进行栈空间分配和初始化
- 程序通过
-
调度过程 ⚡
- P 从本地队列获取 G
- 将 G 交给 M 执行
- 如果本地队列为空,会尝试从全局队列获取 G
- 如果全局队列也为空,会尝试从其他 P"偷取"G
- 每个 M 都有一个 G0,用于执行调度任务
- G0 的栈空间大小是固定的,不会动态调整
- G0 在整个程序的生命周期内只有一个
-
系统调用 🔄
- 当 G 进行系统调用时,M 会释放 P
- P 会被分配给其他空闲的 M
- 系统调用结束后,G 会重新进入队列等待调度
- 使用 hand off 机制,避免线程阻塞
- 系统调用期间,M 会切换到 G0 执行调度任务
# GMP 的调度策略 🎯
# 1. 工作窃取(Work Stealing)🦹♂️
- 当 P 的本地队列为空时
- 会随机选择一个 P,尝试从其本地队列 "偷取" 一半的 G
- 这种机制可以平衡各个 P 的工作负载
- 避免资源浪费和线程饥饿
- 窃取时会考虑负载均衡
# 2. 自旋线程(Spinning Threads)⚡
- 部分 M 会处于自旋状态
- 自旋的 M 会不断寻找可执行的 G
- 避免频繁的线程创建和销毁
- 提高响应速度
- 自旋线程数量由 GOMAXPROCS 决定
# 3. 全局队列(Global Queue)🌍
- 存放等待调度的 G
- 当 P 的本地队列满时,会将 G 放入全局队列
- 优先级低于本地队列
- 用于负载均衡
- 全局队列的访问需要加锁
# 4. 抢占机制(Preemption)⚡
- sysmon 线程监控 goroutine 运行时间
- 超过阈值时触发抢占
- 通过 timer 实现定时抢占
- 避免 goroutine 长时间占用资源
- 支持协作式调度和抢占式调度
# GMP 的优势 💪
-
高效的内存使用 💾
- G 的栈大小动态调整
- 避免固定栈大小带来的内存浪费
- G0 使用固定栈,避免栈溢出
- 支持栈的自动扩容和收缩
-
优秀的并发性能 🚀
- 充分利用多核 CPU
- 减少线程切换开销
- 支持大量并发 Goroutine
- 动态负载均衡
- 高效的调度算法
-
灵活的调度策略 🎮
- 支持工作窃取
- 动态负载均衡
- 避免线程饥饿
- 抢占式调度
- 支持协作式调度
# 实际应用建议 💡
-
合理设置 GOMAXPROCS ⚙️
runtime.GOMAXPROCS(runtime.NumCPU())
-
避免创建过多 Goroutine ⚠️
- 使用 goroutine 池
- 控制并发数量
- 注意内存使用
- 避免 goroutine 泄漏
-
注意系统调用 🔄
- 系统调用会阻塞 M
- 考虑使用异步 IO
- 避免频繁的系统调用
- 使用 syscall.Syscall 替代 syscall.Syscall6
-
性能优化建议 🎯
- 合理使用 goroutine
- 避免 goroutine 泄漏
- 使用 sync.Pool 复用对象
- 注意锁的使用
- 使用原子操作代替锁
- 避免不必要的 goroutine 创建
# 总结 📝
GMP 模型是 Go 语言实现高并发的核心机制,它通过 Goroutine、Machine 和 Processor 三个组件的协同工作,实现了高效的并发调度。理解 GMP 模型对于编写高性能的 Go 程序至关重要!
记住:Go 的并发哲学是 "通过通信来共享内存,而不是通过共享内存来通信" 🎯
# 关键点回顾 🔍
- G0 是每个 M 的特殊 goroutine,用于调度
- M0 是主线程,负责程序初始化
- P0 是主处理器,负责执行 main goroutine
- 工作窃取机制确保负载均衡
- 抢占机制避免 goroutine 饥饿
- 系统调用时 M 会切换到 G0
- G0 使用固定栈,避免栈溢出
# 2. 核心数据结构 🏗️
gmp 数据结构定义在 runtime/runtime2.go 文件中 📁
# 2.1 g 🏃♂️
type g struct { | |
stack stack // 当前 goroutine 的栈空间范围 [l0,hi] | |
stackguard0 uintptr // 栈溢出检测阈值,正常为 stack.lo + StackGuard,抢占时为 StackPreempt | |
stackguard1 uintptr //systemstack 专用栈溢出检测阈值 | |
_panic *_panic // 当前 g 的最内层 panic 结构指针 | |
_defer *_defer // 当前 g 的最内层 defer 结构指针 | |
m *m // 当前 g 绑定的 M,用于调度和状态管理 | |
sched gobuf // 保存 g 的寄存器上下文(sp/pc 等),用于切换 | |
syscallsp uintptr // 系统调用时保存的 sp,供 GC 和回溯使用 | |
syscallpc uintptr // 系统调用时保存的 pc,供 GC 和回溯使用 | |
stktopsp uintptr // 栈顶 sp 期望值,回溯时校验用 | |
param unsafe.Pointer // 通用参数指针,调度 / 唤醒 / GC 等场景临时传递数据 | |
atomicstatus atomic.Uint32 //g 的状态(_Grunning/_Grunnable 等),原子操作 | |
stackLock uint32 // 栈锁,sigprof/scang 用,防止并发栈操作 | |
goid uint64 //goroutine 唯一 ID | |
schedlink guintptr // 调度队列中的链表指针 | |
waitsince int64 //g 进入阻塞状态的时间戳 | |
waitreason waitReason //g 阻塞的原因(如 channel、GC 等) | |
preempt bool // 抢占信号,true 表示请求抢占 | |
preemptStop bool // 抢占后是否进入_Gpreempted 状态 | |
preemptShrink bool // 是否在安全点收缩栈 | |
asyncSafePoint bool // 是否停在异步安全点(栈帧缺乏精确指针信息) | |
paniconfault bool // 非预期 fault 地址时 panic(否则 crash) | |
gcscandone bool // 栈是否已被 GC 扫描 | |
throwsplit bool // 禁止栈分裂(扩容) | |
activeStackChans bool // 栈上有未锁定 channel,栈搬移需加锁保护 | |
parkingOnChan atomic.Bool // 即将因 chan 操作停车,标记栈收缩不安全点 | |
inMarkAssist bool // 是否处于 GC 标记协助状态 | |
coroexit bool // 协程切换参数 | |
raceignore int8 // 是否忽略 race 检测 | |
nocgocallback bool // 禁止 C 回调 | |
tracking bool // 是否追踪调度延迟 | |
trackingSeq uint8 // 追踪序列号 | |
trackingStamp int64 // 追踪开始时间戳 | |
runnableTime int64 // 可运行状态累计时间 | |
lockedm muintptr //g 锁定的 m(LockOSThread 场景) | |
sig uint32 // 信号编号 | |
writebuf []byte // 信号 / 系统调用写缓冲区 | |
sigcode0 uintptr // 信号相关参数 | |
sigcode1 uintptr // 信号相关参数 | |
sigpc uintptr // 信号发生时的 PC | |
parentGoid uint64 // 创建本 g 的父 goroutine 的 goid | |
gopc uintptr // 创建本 g 的 go 语句的 PC | |
ancestors *[]ancestorInfo // 创建链信息(debug 用) | |
startpc uintptr //goroutine 函数入口 PC | |
racectx uintptr //race 检测上下文 | |
waiting *sudog //g 正在等待的 sudog 链表 | |
cgoCtxt []uintptr //cgo 回溯上下文 | |
labels unsafe.Pointer //profiler 标签 | |
timer *timer //time.Sleep 复用的 timer | |
selectDone atomic.Uint32 //select 竞态标记 | |
coroarg *coro // 协程切换参数 | |
goroutineProfiled goroutineProfileStateHolder // 当前 profile 状态 | |
trace gTraceState //trace 状态 | |
gcAssistBytes int64 // GC 助力记账,正值有 credit,负值需协助 GC | |
} |
g 的生命周期: 🔄
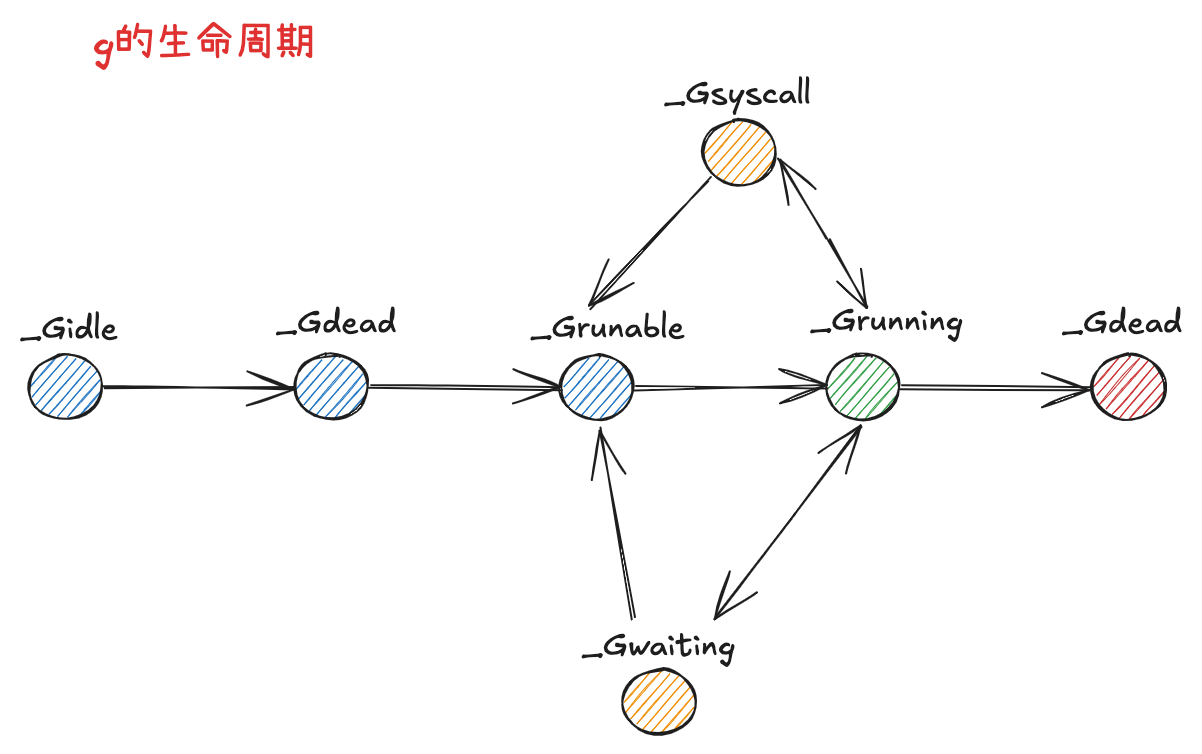
const ( | |
_Gidle = iota // 0 | |
_Grunnable // 1 | |
_Grunning // 2 | |
_Gsyscall // 3 | |
_Gwaiting // 4 | |
_Gmoribund_unused // 5 | |
_Gdead // 6 | |
// _Genqueue_unused is currently unused. | |
_Genqueue_unused // 7 | |
_Gcopystack // 8 | |
_Gpreempted // 9 | |
_Gscan = 0x1000 | |
_Gscanrunnable = _Gscan + _Grunnable // 0x1001 | |
_Gscanrunning = _Gscan + _Grunning // 0x1002 | |
_Gscansyscall = _Gscan + _Gsyscall // 0x1003 | |
_Gscanwaiting = _Gscan + _Gwaiting // 0x1004 | |
_Gscanpreempted = _Gscan + _Gpreempted // 0x1009 | |
) |
- _Gidle 值为 0,为协程开始创建时的状态,此时尚未初始化完成 🆕
- _Grunnable 值为 1, 协程在等待执行队列中,等待被执行 ⏳
- _Grunning 值为 2,协程正在执行,同一时刻 p 中只有一个 g 处于此状态 🏃♂️
- _Gsyscall 值为 3,协程正在执行系统调用 🔧
- _Gwaiting 值为 4,协程处于挂起状态,需要等待被唤醒。gc、channel 通信或者锁操作时经常会进入这种状态 😴
- _Gdead 值为 6,协程初始化完成或者已经被销毁,会处于此状态 💀
- _Gcopystack 值为 8,协程正在栈扩容流程中 📈
- _Greempted 值为 9,协程被抢占后的状态 ⚡
# 2.2 m ⚙️
type m struct { | |
g0 *g // 调度专用的 goroutine(g0),用于执行调度、GC、系统调用等,不运行用户代码 | |
morebuf gobuf //morestack 切换时的参数缓冲区 | |
divmod uint32 // ARM 架构除法 / 取模用的分母,汇编用 | |
_ uint32 // 内存对齐 | |
// Fields not known to debuggers. | |
procid uint64 // 操作系统线程 ID(如 pthread id),调试器用 | |
gsignal *g // 信号处理专用 goroutine | |
goSigStack gsignalStack // Go 分配的信号处理栈 | |
sigmask sigset // 保存的信号掩码 | |
tls [tlsSlots]uintptr // 线程本地存储(TLS),如 x86 的 extern register,tls [0] 存储当前 g | |
mstartfn func() // 线程启动时执行的函数 | |
curg *g // 当前正在运行的 goroutine | |
caughtsig guintptr // 发生致命信号时正在运行的 goroutine | |
p puintptr // 当前绑定的 P(处理器),执行 go 代码时非 nil | |
nextp puintptr // 下一个要绑定的 P | |
oldp puintptr // 系统调用前绑定的 P,syscall 返回后优先恢复 | |
id int64 //m 的唯一 ID | |
mallocing int32 // 是否正在 malloc | |
throwing throwType // 是否正在 panic/throw | |
preemptoff string // 非空时禁止抢占,保持 curg 一直运行在此 m 上 | |
locks int32 // 当前持有的锁数量 | |
dying int32 //m 是否即将退出 | |
profilehz int32 // CPU profiler 采样频率 | |
spinning bool //m 是否处于自旋状态,主动寻找可执行 g | |
blocked bool //m 是否被阻塞在 note 上 | |
newSigstack bool // 是否已为 C 线程调用 sigaltstack | |
printlock int8 //print 锁 | |
incgo bool // 是否正在执行 cgo 调用 | |
isextra bool // 是否为额外创建的 m | |
isExtraInC bool // 额外 m 是否正在执行 C 代码 | |
isExtraInSig bool // 额外 m 是否在信号处理器中 | |
freeWait atomic.Uint32 // 是否可以安全释放 g0 和删除 m | |
needextram bool // 是否需要额外的 m | |
traceback uint8 // 是否允许 traceback | |
ncgocall uint64 // 累计 cgo 调用次数 | |
ncgo int32 // 当前正在进行的 cgo 调用数 | |
cgoCallersUse atomic.Uint32 //cgoCallers 临时使用标记 | |
cgoCallers *cgoCallers //cgo 调用回溯信息 | |
park note // 用于阻塞 / 唤醒 m 的同步原语 | |
alllink *m //allm 链表 | |
schedlink muintptr // 调度器链表 | |
lockedg guintptr // 当前锁定的 g(LockOSThread 场景) | |
createstack [32]uintptr // 创建此线程的调用栈 | |
lockedExt uint32 // 外部 LockOSThread 追踪 | |
lockedInt uint32 // 内部 LockOSThread 追踪 | |
nextwaitm muintptr // 下一个等待锁的 m | |
mLockProfile mLockProfile //runtime.lock 竞争相关字段 | |
//wait* 用于 gopark 到 park_m 参数传递(无栈空间时用) | |
waitunlockf func(*g, unsafe.Pointer) bool | |
waitlock unsafe.Pointer | |
waitTraceBlockReason traceBlockReason | |
waitTraceSkip int | |
syscalltick uint32 // 系统调用计数 | |
freelink *m //sched.freem 链表 | |
trace mTraceState //trace 状态 | |
// 这些字段太大,不能放在 NOSPLIT 函数的栈上 | |
libcall libcall | |
libcallpc uintptr // CPU profiler 用 | |
libcallsp uintptr | |
libcallg guintptr | |
syscall libcall // Windows 下存储系统调用参数 | |
vdsoSP uintptr // VDSO 调用时的 SP(回溯用) | |
vdsoPC uintptr // VDSO 调用时的 PC(回溯用) | |
preemptGen atomic.Uint32 // 已完成的抢占信号计数,用于检测抢占请求失败 | |
signalPending atomic.Uint32 // 是否有待处理的抢置信号 | |
pcvalueCache pcvalueCache //pcvalue 查找缓存 | |
dlogPerM //per-m 的调度日志 | |
mOS // OS 相关字段 | |
chacha8 chacha8rand.State //chacha8 随机数状态 | |
cheaprand uint64 // 简易随机数 | |
// 最多 10 个锁,lock ranking 代码维护 | |
locksHeldLen int | |
locksHeld [10]heldLockInfo | |
} |
- g0:一种特殊的调度协程,不用于执行用户函数,负责执行 g 之间的切换调度。与 m 的关系是 1:1 🎯
- tls:thread-local storage,线程本地存储,存储内容只对当前线程可见。线程本地存储的事 m.tls 的地址,m.tls [0] 存储的但是当前运行的 g,因此线程可以通过 g 找到当前的 m、p、g0 等信息 🗄️
# 2.3 P 🎮
type p struct { | |
id int32 // P 的唯一标识 | |
status uint32 // 当前 P 的状态(pidle/prunning 等) | |
link puintptr // 调度器链表指针 | |
schedtick uint32 // 每次调度递增,统计调度次数 | |
syscalltick uint32 // 每次系统调用递增,统计系统调用次数 | |
sysmontick sysmontick //sysmon 线程最后一次观察到的 tick | |
m muintptr // 当前绑定的 M(线程),idle 时为 nil | |
mcache *mcache // 当前 P 的 mcache,分配内存用 | |
pcache pageCache // 当前 P 的 pageCache,页分配缓存 | |
raceprocctx uintptr //race 检测上下文 | |
deferpool []*_defer // 可复用 defer 对象池 | |
deferpoolbuf [32]*_defer //defer 池缓冲区 | |
goidcache uint64 //goroutine id 缓存,减少原子操作 | |
goidcacheend uint64 //goroutine id 缓存上限 | |
runqhead uint32 // 本地可运行 G 队列头 | |
runqtail uint32 // 本地可运行 G 队列尾 | |
runq [256]guintptr // 本地可运行 G 队列,最大 256 | |
runnext guintptr // 优先调度的 G(由当前 G ready 产生,继承时间片) | |
gFree struct { // 已死亡 G 的缓存池 | |
gList | |
n int32 | |
} | |
sudogcache []*sudog //sudog 对象缓存池 | |
sudogbuf [128]*sudog //sudog 池缓冲区 | |
mspancache struct { //mspan 对象缓存池 | |
len int | |
buf [128]*mspan | |
} | |
pinnerCache *pinner //pinner 对象缓存,减少重复分配 | |
trace pTraceState //trace 状态 | |
palloc persistentAlloc // 持久化分配器,避免加锁 | |
timer0When atomic.Int64 //timer 堆首元素的触发时间(0 表示无 timer) | |
timerModifiedEarliest atomic.Int64 // 最早被修改的 timer 的触发时间 | |
gcAssistTime int64 // 当前 P 协助 GC 的累计纳秒数 | |
gcFractionalMarkTime int64 // 当前 P 分数标记 worker 累计纳秒数(原子) | |
limiterEvent limiterEvent // GC CPU 限速事件追踪 | |
gcMarkWorkerMode gcMarkWorkerMode // 下一个 GC 标记 worker 的运行模式 | |
gcMarkWorkerStartTime int64 // 最近一次标记 worker 启动时间 | |
gcw gcWork // 当前 P 的 GC work buffer 缓存 | |
wbBuf wbBuf // 当前 P 的 GC 写屏障缓冲区 | |
runSafePointFn uint32 // 若为 1,下一个安全点运行 safePointFn | |
statsSeq atomic.Uint32 // P 是否正在写统计信息(偶数未写,奇数正在写) | |
timersLock mutex //timer 相关操作的锁 | |
timers []*timer // 定时器堆 | |
numTimers atomic.Uint32 //timer 堆中的 timer 数量 | |
deletedTimers atomic.Uint32 //timer 堆中已删除 timer 数量 | |
timerRaceCtx uintptr // 执行 timer 函数时的 race 上下文 | |
maxStackScanDelta int64 // 活跃 G 持有的栈空间增量,定期刷新到 gcController | |
scannedStackSize uint64 // 本 P 扫描过的 G 的栈空间总大小 | |
scannedStacks uint64 // 本 P 扫描过的 G 数量 | |
preempt bool // 标记 P 需要尽快进入调度器(无论当前 G 状态) | |
pageTraceBuf pageTraceBuf // 页分配 / 释放 / 回收 trace 缓冲区(GOEXPERIMENT=pagetrace 时用) | |
// Padding 已不再需要,p 结构体已足够大,避免伪共享 | |
} |
# 2.4 schedt
type schedt struct { | |
goidgen atomic.Uint64 // 全局 goroutine id 生成器 | |
lastpoll atomic.Int64 // 上次网络轮询时间,0 表示正在轮询 | |
pollUntil atomic.Int64 // 当前网络轮询的休眠截止时间 | |
lock mutex // 全局调度锁 | |
// M 相关全局计数与空闲队列 | |
midle muintptr // 空闲 m 链表 | |
nmidle int32 // 空闲 m 数量 | |
nmidlelocked int32 // 被锁定的空闲 m 数量 | |
mnext int64 // 已创建 m 的数量,下一个 m 的 ID | |
maxmcount int32 // 最大允许的 m 数量,超限则崩溃 | |
nmsys int32 // 系统 m 数量(不计入死锁检测) | |
nmfreed int64 // 已释放 m 的累计数量 | |
ngsys atomic.Int32 // 系统 goroutine 数量 | |
// P 相关全局计数与空闲队列 | |
pidle puintptr // 空闲 p 链表 | |
npidle atomic.Int32 // 空闲 p 数量 | |
nmspinning atomic.Int32 // 正在自旋的 m 数量 | |
needspinning atomic.Uint32 // 是否需要自旋线程(需持 sched.lock 设置) | |
// 全局可运行 goroutine 队列 | |
runq gQueue // 全局可运行 g 队列 | |
runqsize int32 // 全局队列长度 | |
// 调度器禁用控制 | |
disable struct { | |
user bool // 是否禁用用户 goroutine 调度 | |
runnable gQueue // 禁用期间挂起的可运行 g 队列 | |
n int32 // 挂起队列长度 | |
} | |
// 全局 dead G 缓存池 | |
gFree struct { | |
lock mutex | |
stack gList // 有栈的 dead G | |
noStack gList // 无栈的 dead G | |
n int32 | |
} | |
//sudog 对象中央缓存池 | |
sudoglock mutex | |
sudogcache *sudog | |
//defer 对象中央缓存池 | |
deferlock mutex | |
deferpool *_defer | |
// 等待释放的 m 链表(m.exited 后通过 m.freelink 串联) | |
freem *m | |
gcwaiting atomic.Bool // 是否 GC 正在等待 | |
stopwait int32 // 等待 stop 的 P 数量 | |
stopnote note //stop 通知 | |
sysmonwait atomic.Bool //sysmon 是否在等待 | |
sysmonnote note //sysmon 通知 | |
// GC 安全点相关 | |
safePointFn func(*p) // 下次 GC 安全点要在每个 P 上调用的函数 | |
safePointWait int32 // 等待安全点的 P 数量 | |
safePointNote note // 安全点通知 | |
profilehz int32 // CPU 采样频率 | |
procresizetime int64 // 上次 gomaxprocs 变更时间 | |
totaltime int64 //gomaxprocs 积分(用于统计) | |
sysmonlock mutex //sysmon 专用锁,阻止其与 runtime 其它部分交互 | |
// 调度延迟统计 | |
timeToRun timeHistogram // G 从 runnable 到 running 的延迟分布 | |
idleTime atomic.Int64 // 所有 P 累计空闲 CPU 时间,每次 GC 重置 | |
totalMutexWaitTime atomic.Int64 // G 因 mutex/rwmutex 等待的总时间 | |
//stop-the-world 相关统计 | |
stwStoppingTimeGC timeHistogram // GC 相关 STW 的停止延迟分布 | |
stwStoppingTimeOther timeHistogram // 非 GC 相关 STW 的停止延迟分布 | |
stwTotalTimeGC timeHistogram // GC 相关 STW 的总延迟分布 | |
stwTotalTimeOther timeHistogram // 非 GC 相关 STW 的总延迟分布 | |
//runtime 锁等待统计 | |
totalRuntimeLockWaitTime atomic.Int64 // G 在 runtime 锁上等待的总时间(已退出的 M) | |
// 其它字段略... | |
} |
schedt 是全局 goroutine 队列的封装:
- lock:一把操作全局队列时使用的锁
- runq:全局 goroutine 队列
- runqsize:全局 goroutine 队列的容量
# 3. 调度流程
# 3.1 两种 g 的转换
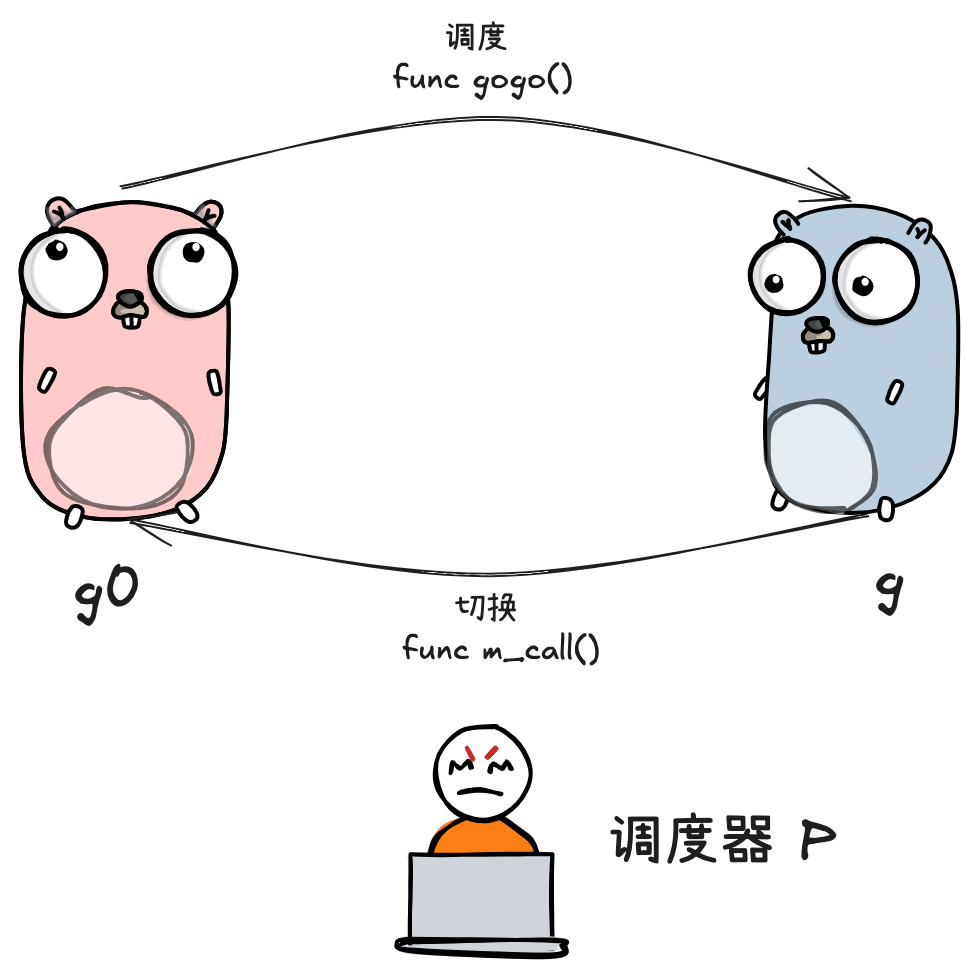
goroutine 的类型可分为两类:
- 负责调度普通 g 的 g0,执行固定的调度流程,与 m 的关系为一对一
- 负责执行用户函数的普通 g
m 通过 p 调度执行的 goroutine 永远在普通 g 和 g0 之间进行切换,当 g0 找到可执行的 g 时,会调用 gogo 方法,调度 g 执行用户定义的任务;
当 g 需要主动让渡或被动调度时,会触发 mcall 方法,将执行权重新交还给 g0
gogo 和 mcall 可以理解为对偶关系,其定义位于 runtime/stubs.go 中
func gogo(buf *gobuf) | |
// ... | |
func mcall(fn func(*g)) |
| 特性 | g0 | 普通 g |
|---|---|---|
| 是否被调度器调度 | 否 | 是 |
| 是否可运行用户代码 | 否 | 是 |
| 是否与 M 绑定 | 是(一个 M 对一个 g0) | 否(可在多个 M 上切换) |
| 栈空间 | 调度器使用 | 用户代码使用 |
| 是否会被挂起 | 不会 | 会 |
| 主要用途 | 调度、syscall、GC、panic | 执行业务逻辑 |
# 3.2 调度类型
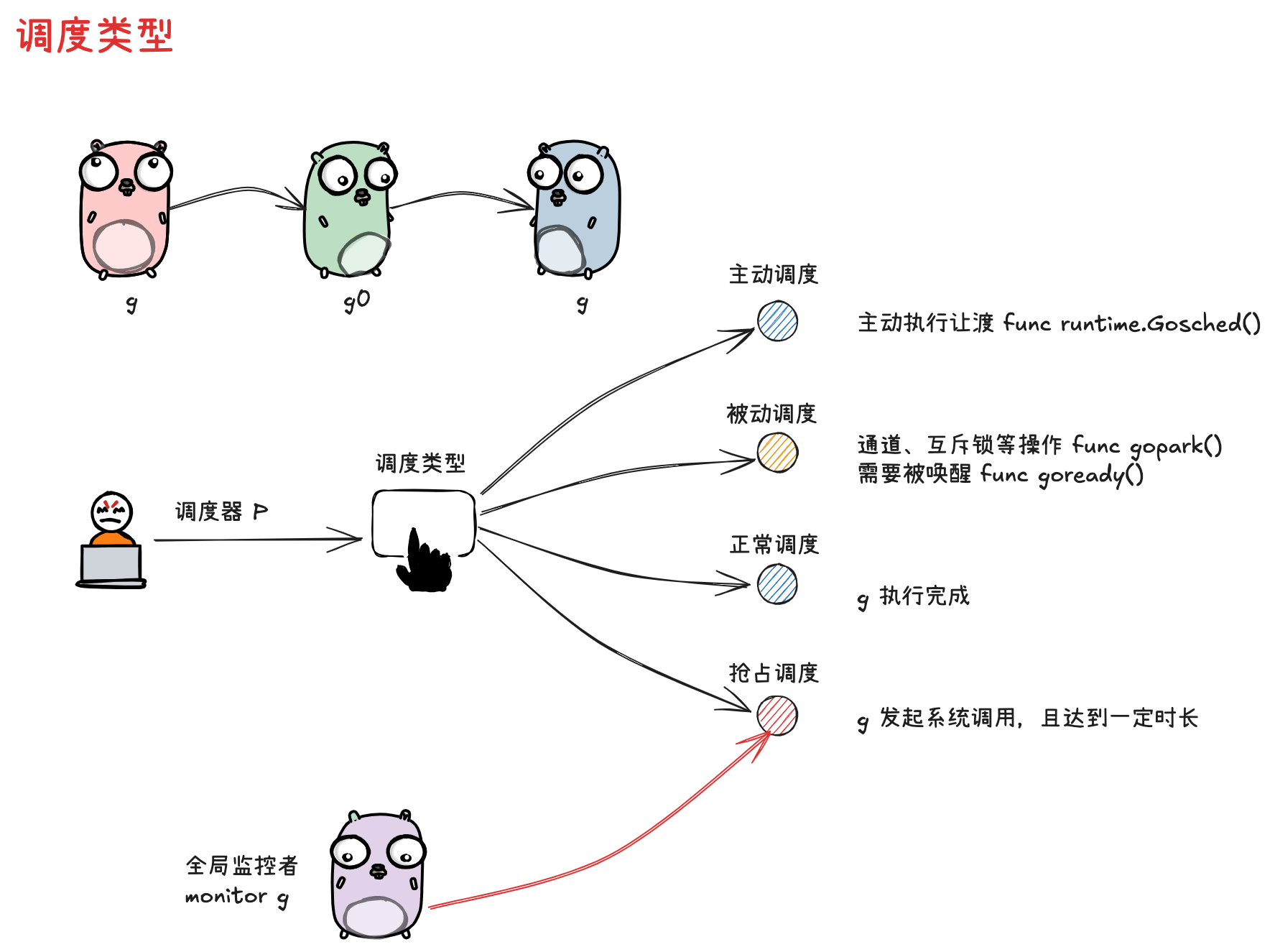
通常,调度指的是由 g0 按照特定策略找到下一个可执行 g 的过程。而本小节谈及的调度类型是广义上的 “调度”,指的是调度器 p 实现从执行一个 g 切换到另一个 g 的过程.
这种广义 “调度” 可分为几种类型:
-
主动调度
一种用户主动执行让渡的方式,主要方式是,用户在执行代码中调用了 runtime.Gosched 方法,此时当前 g 会让出执行权,主动进行队列 等待下次被调度执行。
代码位于
runtime/proc.gofunc Gosched() {
checkTimeouts()
mcall(gosched_m)
} -
被动调度
因当前不满足某种执行条件,g 可能会陷入阻塞态无法被调度,直到所需的条件达成后,g 才从阻塞中被唤醒,重新进入可执行队列等待被调度
代码位于
runtime/proc.gofunc gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waitTraceBlockReason = traceReason
mp.waitTraceSkip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.mcall(park_m)
}goready 方法通常与 gopark 方法成对出现,能够将 g 从阻塞态恢复,重新进入等待执行的状态
代码位于
runtime/proc.gofunc goready(gp *g, traceskip int) {
systemstack(func() {
ready(gp, traceskip, true)
})
} -
正常调度
g 中的执行任务已完成,g0 会将当前 g 置为死亡状态,发起新一轮调度
-
抢占调度
倘若 g 执行系统调用超过指定的时长,且全局的 p 资源比较紧缺,此时将 p 和 g 解绑,抢占出来用于其他 g 的调度。等 g 完成系统调用后,会重新进入可执行队列中等待被调度。
前 3 种调度方式都由 m 下的 g0 完成,唯独抢占调度不同.
因为发起系统调用时需要打破用户态的边界进入内核态,此时 m 也是因系统调用而陷入僵直,无法主动完成抢占调度的行为
因此,在 Golang 进程会由一个全局监控协程 monitor g 的存在,这个 g 会越过 p 直接与一个 m 进行绑定,不断轮询对所有 p 的执行状况进行监控。如果发现满足抢占调度的条件,则会从第三方的角度出手敢于,主动发起该动作。
# 3.3 宏观调度流程
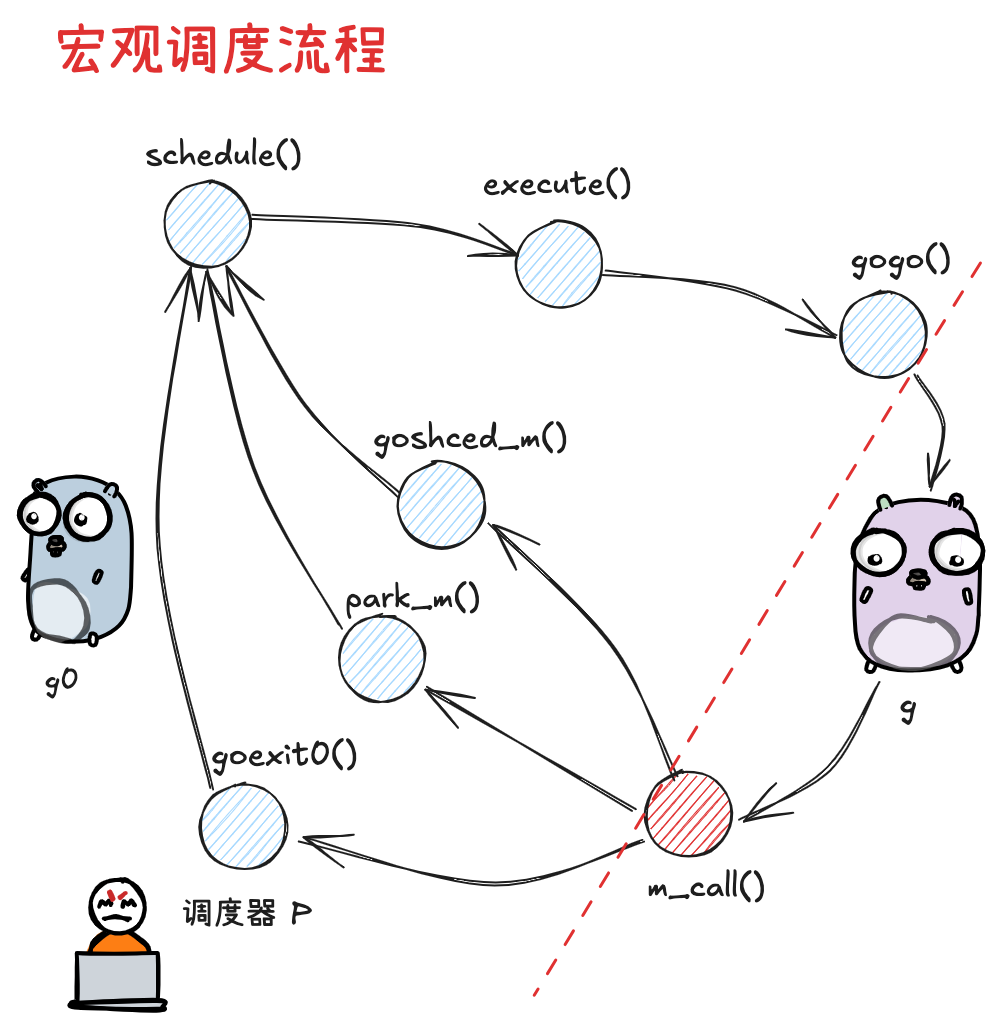
- 以 g0-> g -> g0 的一轮循环为例进行串联
- g0 执行 schedule () 函数,寻找用于执行的 g
- g0 执行 execute () 方法,更新档期啊 g、p 的状态信息,并调用 gogo () 方法,将执行权交给 g
- g 因主动让渡 (goshce_m ())、被动调度 ( park_m () )、正常结束 ( goexit0 () ) 等原因,调用 m_call 函数,执行权重新回到 g0 手中
- g0 执行 schedule () 函数,开启新一轮循环
# 3.4 shcedule
调度流程的主干方法是位于 runtime/proc.go 中的 shcedule 函数,此时的执行权位于 g0 手中:
func schedule() { | |
// ... | |
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available | |
// ... | |
execute(gp, inheritTime) | |
} |
- 寻找到下一个执行的 goroutine
- 执行该 goroutine
# 3.5 findRunable
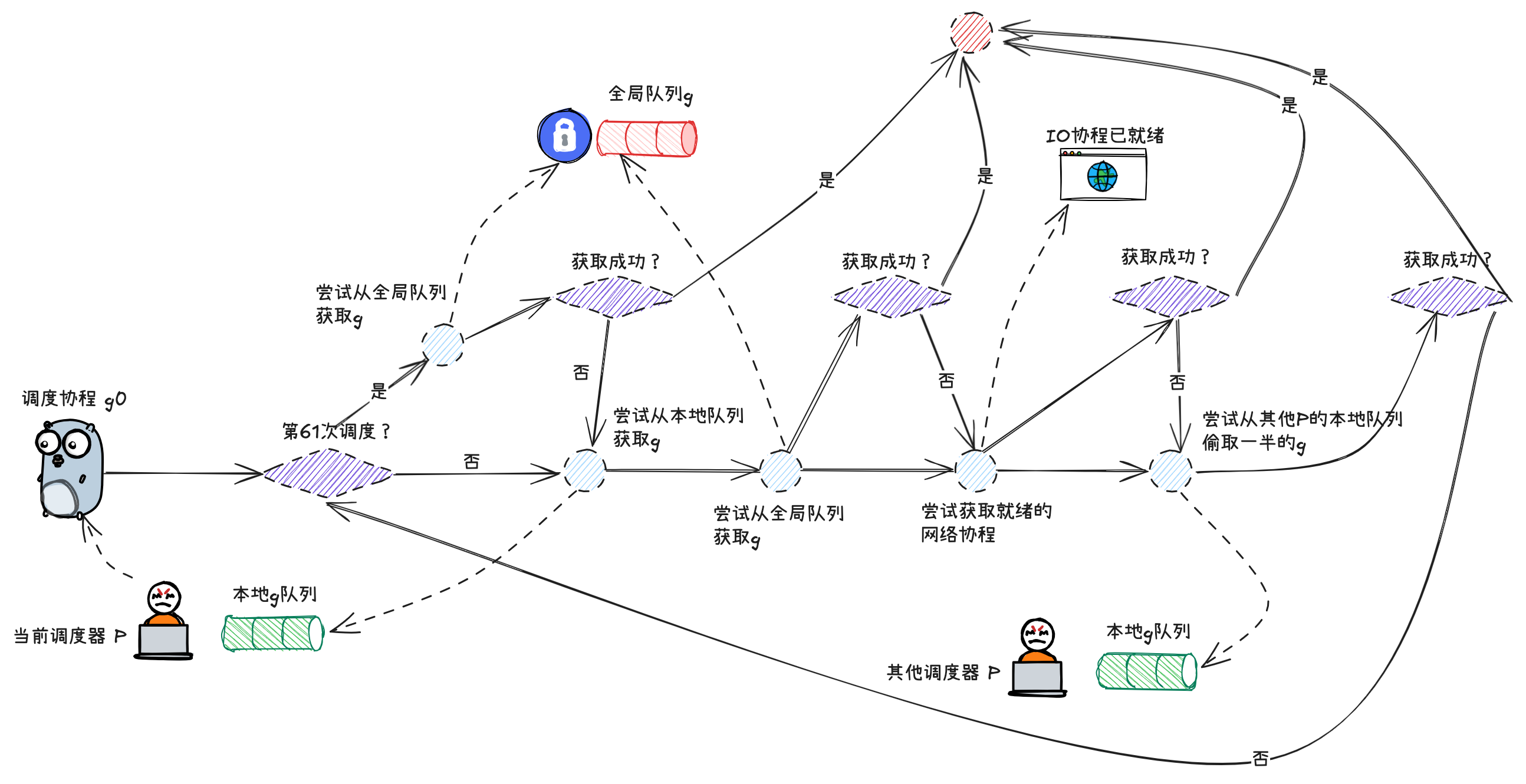
调度流程中,一个非常核心的步骤,就是为 m 寻找下一个执行的 g,这部分内容位于 runtime/proc.go 的 findRunnable 方法中
func findRunnable() (gp *g, inheritTime, tryWakeP bool) { | |
mp := getg().m | |
top: | |
pp := mp.p.ptr() | |
if sched.gcwaiting.Load() { | |
gcstopm() | |
goto top | |
} | |
if pp.runSafePointFn != 0 { | |
runSafePointFn() | |
} | |
// now and pollUntil are saved for work stealing later, | |
// which may steal timers. It's important that between now | |
// and then, nothing blocks, so these numbers remain mostly | |
// relevant. | |
now, pollUntil, _ := pp.timers.check(0) | |
// Try to schedule the trace reader. | |
if traceEnabled() || traceShuttingDown() { | |
gp := traceReader() | |
if gp != nil { | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, true | |
} | |
} | |
// Try to schedule a GC worker. | |
if gcBlackenEnabled != 0 { | |
gp, tnow := gcController.findRunnableGCWorker(pp, now) | |
if gp != nil { | |
return gp, false, true | |
} | |
now = tnow | |
} | |
// Check the global runnable queue once in a while to ensure fairness. | |
// Otherwise two goroutines can completely occupy the local runqueue | |
// by constantly respawning each other. | |
//p 每执行 61 次调度,会从全局队列中获取一个 goroutine 进行执行,并将一个全局对了中的 goroutine 填充到当前 p 的本地队列中 | |
if pp.schedtick%61 == 0 && sched.runqsize > 0 { | |
lock(&sched.lock) | |
// 除了获取一个 g 用于执行外,还会额外将一个 g 从全局队列转移到 p 的本地队列,让全局队列中的 g 也得到更充分的执行机会 | |
gp := globrunqget(pp, 1) | |
unlock(&sched.lock) | |
if gp != nil { | |
return gp, false, false | |
} | |
} | |
// Wake up the finalizer G. | |
if fingStatus.Load()&(fingWait|fingWake) == fingWait|fingWake { | |
if gp := wakefing(); gp != nil { | |
ready(gp, 0, true) | |
} | |
} | |
if *cgo_yield != nil { | |
asmcgocall(*cgo_yield, nil) | |
} | |
// local runq | |
if gp, inheritTime := runqget(pp); gp != nil { | |
return gp, inheritTime, false | |
} | |
// global runq | |
if sched.runqsize != 0 { | |
lock(&sched.lock) | |
gp := globrunqget(pp, 0) | |
unlock(&sched.lock) | |
if gp != nil { | |
return gp, false, false | |
} | |
} | |
// Poll network. | |
// This netpoll is only an optimization before we resort to stealing. | |
// We can safely skip it if there are no waiters or a thread is blocked | |
// in netpoll already. If there is any kind of logical race with that | |
// blocked thread (e.g. it has already returned from netpoll, but does | |
// not set lastpoll yet), this thread will do blocking netpoll below | |
// anyway. | |
if netpollinited() && netpollAnyWaiters() && sched.lastpoll.Load() != 0 { | |
if list, delta := netpoll(0); !list.empty() { // non-blocking | |
gp := list.pop() | |
injectglist(&list) | |
netpollAdjustWaiters(delta) | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, false | |
} | |
} | |
// Spinning Ms: steal work from other Ps. | |
// | |
// Limit the number of spinning Ms to half the number of busy Ps. | |
// This is necessary to prevent excessive CPU consumption when | |
// GOMAXPROCS>>1 but the program parallelism is low. | |
if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() { | |
if !mp.spinning { | |
mp.becomeSpinning() | |
} | |
gp, inheritTime, tnow, w, newWork := stealWork(now) | |
if gp != nil { | |
// Successfully stole. | |
return gp, inheritTime, false | |
} | |
if newWork { | |
// There may be new timer or GC work; restart to | |
// discover. | |
goto top | |
} | |
now = tnow | |
if w != 0 && (pollUntil == 0 || w < pollUntil) { | |
// Earlier timer to wait for. | |
pollUntil = w | |
} | |
} | |
// We have nothing to do. | |
// | |
// If we're in the GC mark phase, can safely scan and blacken objects, | |
// and have work to do, run idle-time marking rather than give up the P. | |
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) && gcController.addIdleMarkWorker() { | |
node := (*gcBgMarkWorkerNode)(gcBgMarkWorkerPool.pop()) | |
if node != nil { | |
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode | |
gp := node.gp.ptr() | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, false | |
} | |
gcController.removeIdleMarkWorker() | |
} | |
// wasm only: | |
// If a callback returned and no other goroutine is awake, | |
// then wake event handler goroutine which pauses execution | |
// until a callback was triggered. | |
gp, otherReady := beforeIdle(now, pollUntil) | |
if gp != nil { | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, false | |
} | |
if otherReady { | |
goto top | |
} | |
// Before we drop our P, make a snapshot of the allp slice, | |
// which can change underfoot once we no longer block | |
// safe-points. We don't need to snapshot the contents because | |
// everything up to cap(allp) is immutable. | |
allpSnapshot := allp | |
// Also snapshot masks. Value changes are OK, but we can't allow | |
// len to change out from under us. | |
idlepMaskSnapshot := idlepMask | |
timerpMaskSnapshot := timerpMask | |
// return P and block | |
lock(&sched.lock) | |
if sched.gcwaiting.Load() || pp.runSafePointFn != 0 { | |
unlock(&sched.lock) | |
goto top | |
} | |
if sched.runqsize != 0 { | |
gp := globrunqget(pp, 0) | |
unlock(&sched.lock) | |
return gp, false, false | |
} | |
if !mp.spinning && sched.needspinning.Load() == 1 { | |
// See "Delicate dance" comment below. | |
mp.becomeSpinning() | |
unlock(&sched.lock) | |
goto top | |
} | |
if releasep() != pp { | |
throw("findrunnable: wrong p") | |
} | |
now = pidleput(pp, now) | |
unlock(&sched.lock) | |
wasSpinning := mp.spinning | |
if mp.spinning { | |
mp.spinning = false | |
if sched.nmspinning.Add(-1) < 0 { | |
throw("findrunnable: negative nmspinning") | |
} | |
lock(&sched.lock) | |
if sched.runqsize != 0 { | |
pp, _ := pidlegetSpinning(0) | |
if pp != nil { | |
gp := globrunqget(pp, 0) | |
if gp == nil { | |
throw("global runq empty with non-zero runqsize") | |
} | |
unlock(&sched.lock) | |
acquirep(pp) | |
mp.becomeSpinning() | |
return gp, false, false | |
} | |
} | |
unlock(&sched.lock) | |
pp := checkRunqsNoP(allpSnapshot, idlepMaskSnapshot) | |
if pp != nil { | |
acquirep(pp) | |
mp.becomeSpinning() | |
goto top | |
} | |
// Check for idle-priority GC work again. | |
pp, gp := checkIdleGCNoP() | |
if pp != nil { | |
acquirep(pp) | |
mp.becomeSpinning() | |
// Run the idle worker. | |
pp.gcMarkWorkerMode = gcMarkWorkerIdleMode | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, false | |
} | |
// Finally, check for timer creation or expiry concurrently with | |
// transitioning from spinning to non-spinning. | |
// | |
// Note that we cannot use checkTimers here because it calls | |
// adjusttimers which may need to allocate memory, and that isn't | |
// allowed when we don't have an active P. | |
pollUntil = checkTimersNoP(allpSnapshot, timerpMaskSnapshot, pollUntil) | |
} | |
// Poll network until next timer. | |
if netpollinited() && (netpollAnyWaiters() || pollUntil != 0) && sched.lastpoll.Swap(0) != 0 { | |
sched.pollUntil.Store(pollUntil) | |
if mp.p != 0 { | |
throw("findrunnable: netpoll with p") | |
} | |
if mp.spinning { | |
throw("findrunnable: netpoll with spinning") | |
} | |
delay := int64(-1) | |
if pollUntil != 0 { | |
if now == 0 { | |
now = nanotime() | |
} | |
delay = pollUntil - now | |
if delay < 0 { | |
delay = 0 | |
} | |
} | |
if faketime != 0 { | |
// When using fake time, just poll. | |
delay = 0 | |
} | |
list, delta := netpoll(delay) // block until new work is available | |
// Refresh now again, after potentially blocking. | |
now = nanotime() | |
sched.pollUntil.Store(0) | |
sched.lastpoll.Store(now) | |
if faketime != 0 && list.empty() { | |
// Using fake time and nothing is ready; stop M. | |
// When all M's stop, checkdead will call timejump. | |
stopm() | |
goto top | |
} | |
lock(&sched.lock) | |
pp, _ := pidleget(now) | |
unlock(&sched.lock) | |
if pp == nil { | |
injectglist(&list) | |
netpollAdjustWaiters(delta) | |
} else { | |
acquirep(pp) | |
if !list.empty() { | |
gp := list.pop() | |
injectglist(&list) | |
netpollAdjustWaiters(delta) | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 0) | |
traceRelease(trace) | |
} | |
return gp, false, false | |
} | |
if wasSpinning { | |
mp.becomeSpinning() | |
} | |
goto top | |
} | |
} else if pollUntil != 0 && netpollinited() { | |
pollerPollUntil := sched.pollUntil.Load() | |
if pollerPollUntil == 0 || pollerPollUntil > pollUntil { | |
netpollBreak() | |
} | |
} | |
stopm() | |
goto top | |
} |
# 3.6 execute
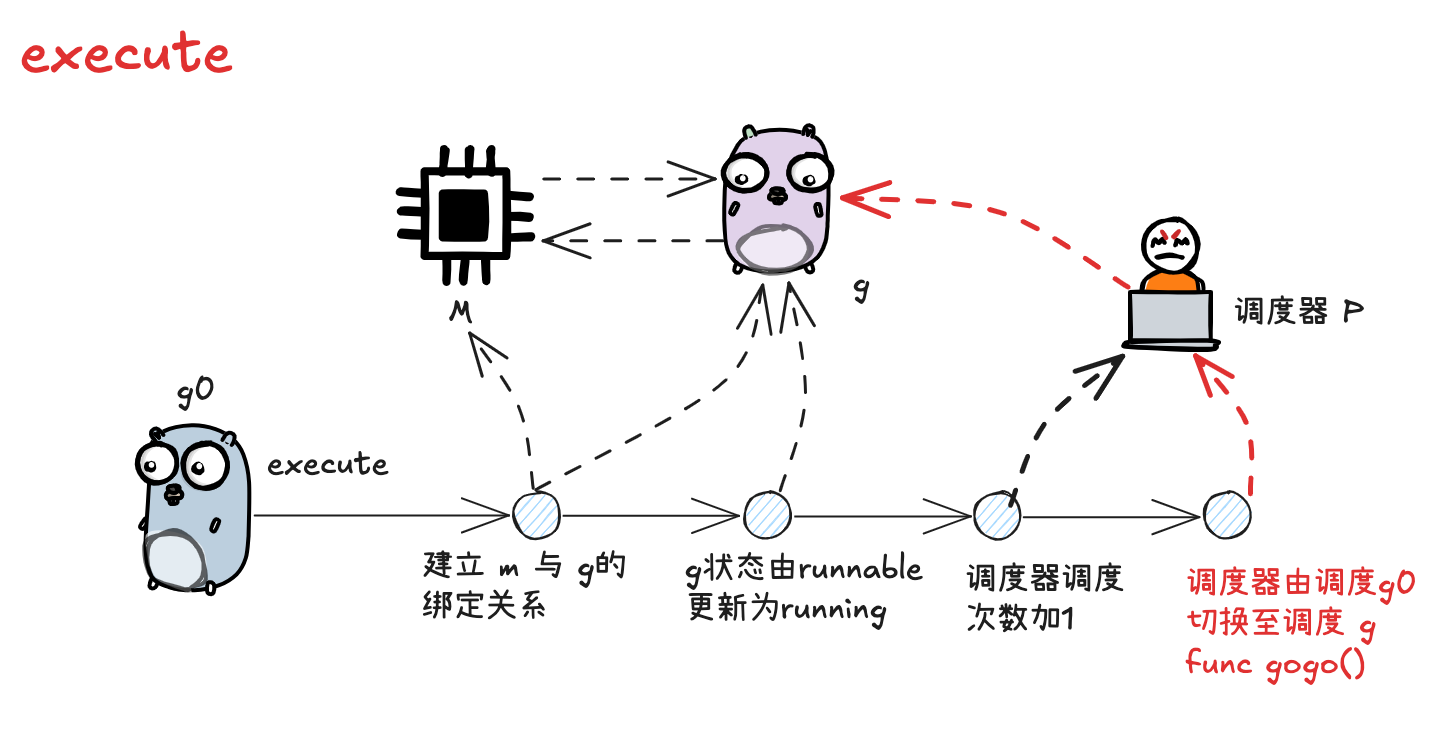
当 g0 为 m 寻找到可执行的 g 之后,接下来就开始执行 g
这部分内容位于 runtime/proc.go 的 execute 方法中:
func execute(gp *g, inheritTime bool) { | |
mp := getg().m | |
if goroutineProfile.active { | |
// Make sure that gp has had its stack written out to the goroutine | |
// profile, exactly as it was when the goroutine profiler first stopped | |
// the world. | |
tryRecordGoroutineProfile(gp, nil, osyield) | |
} | |
// Assign gp.m before entering _Grunning so running Gs have an | |
// M. | |
mp.curg = gp | |
gp.m = mp | |
casgstatus(gp, _Grunnable, _Grunning) | |
gp.waitsince = 0 | |
gp.preempt = false | |
gp.stackguard0 = gp.stack.lo + stackGuard | |
if !inheritTime { | |
mp.p.ptr().schedtick++ | |
} | |
// Check whether the profiler needs to be turned on or off. | |
hz := sched.profilehz | |
if mp.profilehz != hz { | |
setThreadCPUProfiler(hz) | |
} | |
trace := traceAcquire() | |
if trace.ok() { | |
trace.GoStart() | |
traceRelease(trace) | |
} | |
gogo(&gp.sched) | |
} |
- 更新 g 的状态信息,建立 g 与 m 之间的绑定关系
- 更新 p 的总调度次数
- 调用 gogo 方法,执行 goroutine 中的任务
# 3.7 gosched_m
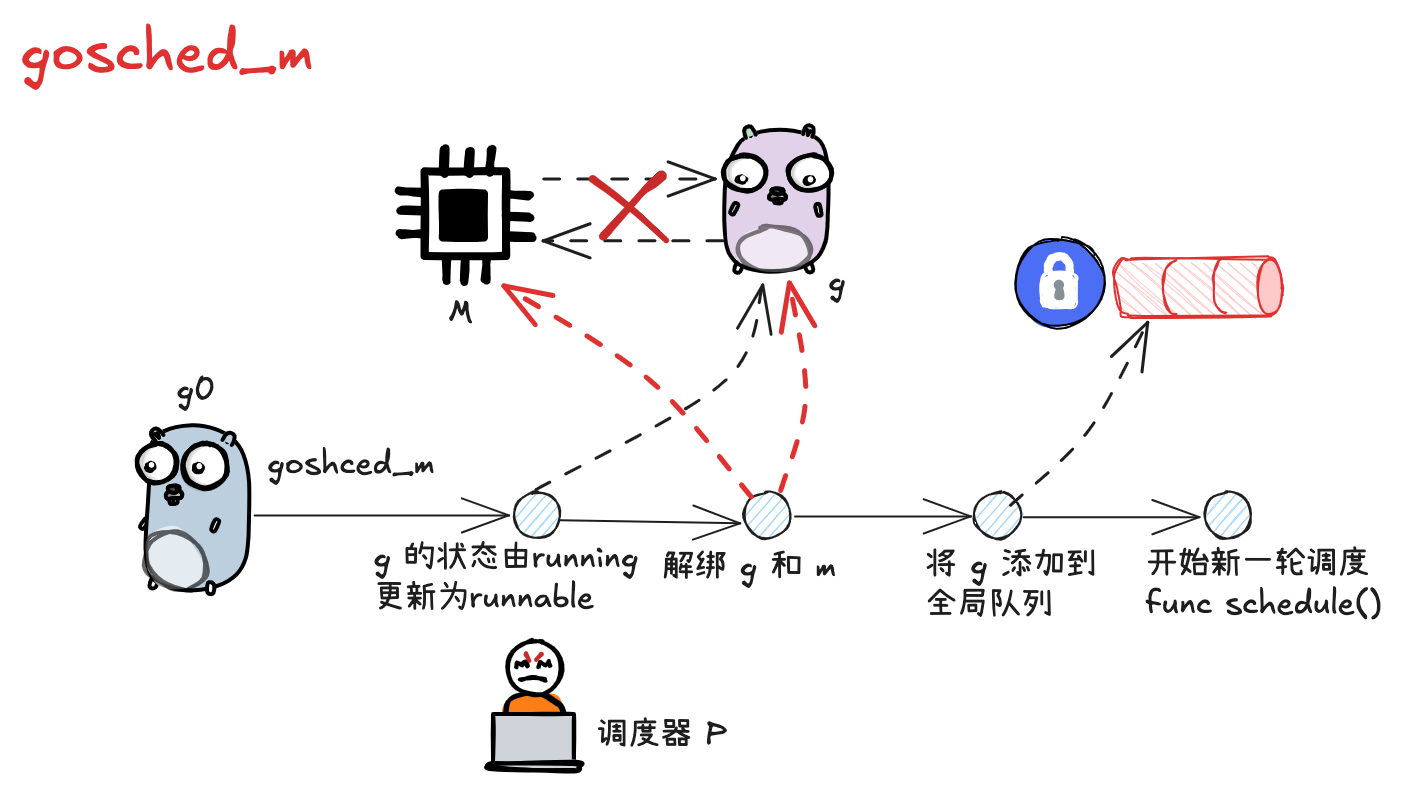
g 执行主动让渡时,会调用 mcall 方法将执行权归还给 g0,并由 g0 调用 gosched_m 方法,位于 runtime/proc.go
func Gosched() { | |
checkTimeouts() | |
mcall(gosched_m) | |
} | |
func gosched_m(gp *g) { | |
goschedImpl(gp, false) | |
} | |
func goschedImpl(gp *g, preempted bool) { | |
trace := traceAcquire() | |
status := readgstatus(gp) | |
if status&^_Gscan != _Grunning { | |
dumpgstatus(gp) | |
throw("bad g status") | |
} | |
if trace.ok() { | |
// Trace the event before the transition. It may take a | |
// stack trace, but we won't own the stack after the | |
// transition anymore. | |
if preempted { | |
trace.GoPreempt() | |
} else { | |
trace.GoSched() | |
} | |
} | |
// 将当前 g 的状态由执行中切换为待执行 _Grunnable | |
casgstatus(gp, _Grunning, _Grunnable) | |
if trace.ok() { | |
traceRelease(trace) | |
} | |
// 调用 dropg (),将当前的 m 和 g 解绑 | |
dropg() | |
// 将 g 添加到全局队列中 | |
lock(&sched.lock) | |
globrunqput(gp) | |
unlock(&sched.lock) | |
if mainStarted { | |
wakep() | |
} | |
// 开启新一轮的调度 | |
schedule() | |
} |
# 3.8 park_m 与 ready
G 需要被动调度时,会调用 mcall 方法切换至 g0, 并调用 park_m 方法将 g 置为阻塞态,执行流程位于 runtime/proc.go 的 gopark 方法中
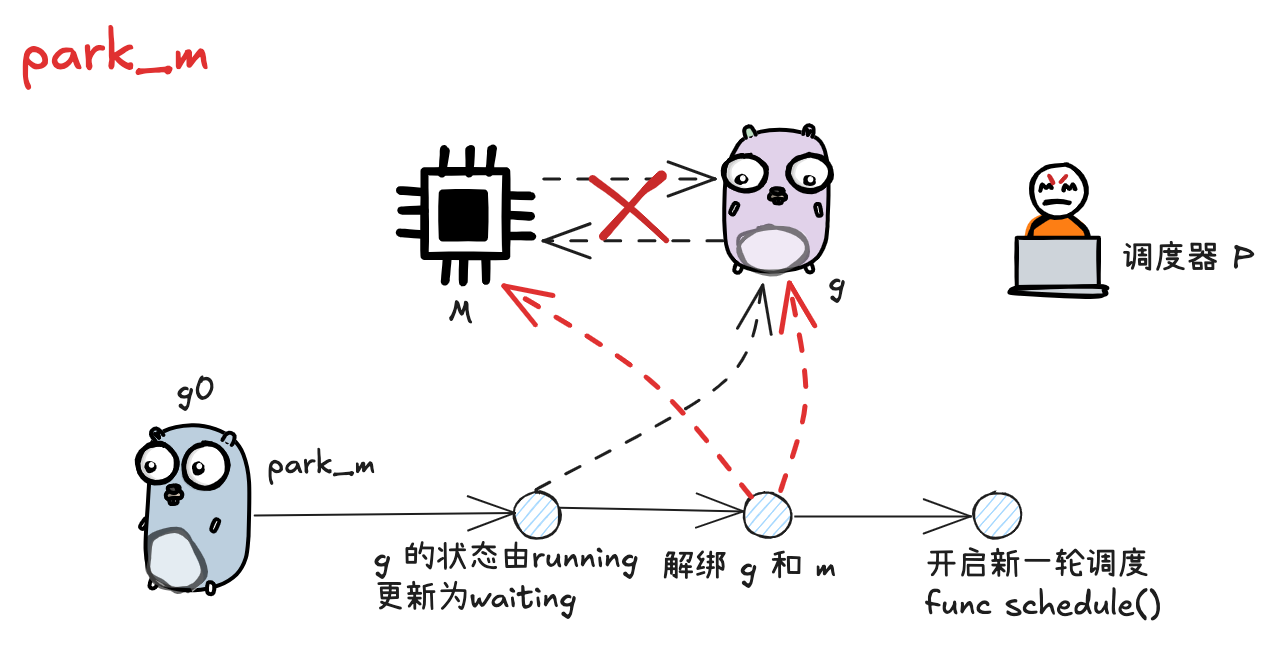
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceReason traceBlockReason, traceskip int) { | |
// ...... | |
mcall(park_m) | |
} |
func park_m(gp *g) { | |
mp := getg().m | |
trace := traceAcquire() | |
if trace.ok() { | |
// Trace the event before the transition. It may take a | |
// stack trace, but we won't own the stack after the | |
// transition anymore. | |
trace.GoPark(mp.waitTraceBlockReason, mp.waitTraceSkip) | |
} | |
// N.B. Not using casGToWaiting here because the waitreason is | |
// set by park_m's caller. | |
// 将当前 g 的状态由 running 改为 waiting | |
casgstatus(gp, _Grunning, _Gwaiting) | |
if trace.ok() { | |
traceRelease(trace) | |
} | |
// 将 g 与 m 解绑 | |
dropg() | |
if fn := mp.waitunlockf; fn != nil { | |
ok := fn(gp, mp.waitlock) | |
mp.waitunlockf = nil | |
mp.waitlock = nil | |
if !ok { | |
trace := traceAcquire() | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, 2) | |
traceRelease(trace) | |
} | |
execute(gp, true) // Schedule it back, never returns. | |
} | |
} | |
// 执行新一轮的调度 | |
schedule() | |
} |
当因被动陷入阻塞态的 g 需要被唤醒时,会由其他协程执行 goready 方法将 g 重置为可执行的状态,方法位于 runtime/proc.go
被动调度如果需要唤醒,则由其他 g 负责将 g 的状态 waiting 改为 runnable, 然后会将其添加到唤醒者的 p 的本地队列中:
func goready(gp *g, traceskip int) { | |
systemstack(func() { | |
ready(gp, traceskip, true) | |
}) | |
} | |
func ready(gp *g, traceskip int, next bool) { | |
status := readgstatus(gp) | |
// Mark runnable. | |
mp := acquirem() // disable preemption because it can be holding p in a local var | |
if status&^_Gscan != _Gwaiting { | |
dumpgstatus(gp) | |
throw("bad g->status in ready") | |
} | |
// status is Gwaiting or Gscanwaiting, make Grunnable and put on runq | |
trace := traceAcquire() | |
// 将 g 的状态从阻塞态改为可执行的状态 | |
casgstatus(gp, _Gwaiting, _Grunnable) | |
if trace.ok() { | |
trace.GoUnpark(gp, traceskip) | |
traceRelease(trace) | |
} | |
// 调用 runqput 将当前 g 添加到唤醒者 p 的本地队列中,如果队列满了,会连带 g 一起将一半的元素转移到全局队列 | |
runqput(mp.p.ptr(), gp, next) | |
wakep() | |
releasem(mp) | |
} |
# 3.9 goexit0
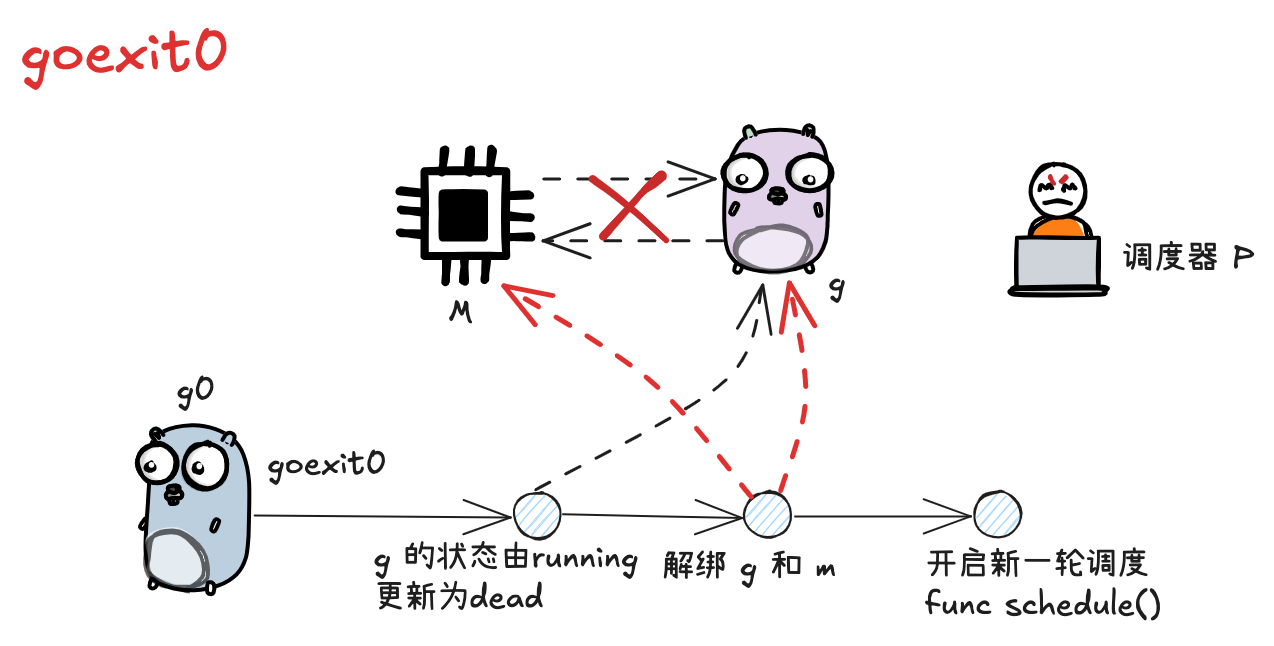
当 g 执行完成时,会先执行 mcall 方法切换至 g0,然后调用 goexit0 方法,runtime/proc.go
func goexit1() { | |
mcall(goexit0) | |
} | |
func goexit0(gp *g) { | |
gdestroy(gp) | |
// 开启新一轮调度 | |
schedule() | |
} | |
func gdestroy(gp *g) { | |
mp := getg().m | |
pp := mp.p.ptr() | |
// 将 g 状态置为 dead | |
casgstatus(gp, _Grunning, _Gdead) | |
gcController.addScannableStack(pp, -int64(gp.stack.hi-gp.stack.lo)) | |
if isSystemGoroutine(gp, false) { | |
sched.ngsys.Add(-1) | |
} | |
gp.m = nil | |
locked := gp.lockedm != 0 | |
gp.lockedm = 0 | |
mp.lockedg = 0 | |
gp.preemptStop = false | |
gp.paniconfault = false | |
gp._defer = nil // should be true already but just in case. | |
gp._panic = nil // non-nil for Goexit during panic. points at stack-allocated data. | |
gp.writebuf = nil | |
gp.waitreason = waitReasonZero | |
gp.param = nil | |
gp.labels = nil | |
gp.timer = nil | |
if gcBlackenEnabled != 0 && gp.gcAssistBytes > 0 { | |
// Flush assist credit to the global pool. This gives | |
// better information to pacing if the application is | |
// rapidly creating an exiting goroutines. | |
assistWorkPerByte := gcController.assistWorkPerByte.Load() | |
scanCredit := int64(assistWorkPerByte * float64(gp.gcAssistBytes)) | |
gcController.bgScanCredit.Add(scanCredit) | |
gp.gcAssistBytes = 0 | |
} | |
// 解绑 g 和 m | |
dropg() | |
if GOARCH == "wasm" { // no threads yet on wasm | |
gfput(pp, gp) | |
return | |
} | |
if locked && mp.lockedInt != 0 { | |
print("runtime: mp.lockedInt = ", mp.lockedInt, "\n") | |
throw("exited a goroutine internally locked to the OS thread") | |
} | |
gfput(pp, gp) | |
if locked { | |
// The goroutine may have locked this thread because | |
// it put it in an unusual kernel state. Kill it | |
// rather than returning it to the thread pool. | |
// Return to mstart, which will release the P and exit | |
// the thread. | |
if GOOS != "plan9" { // See golang.org/issue/22227. | |
gogo(&mp.g0.sched) | |
} else { | |
// Clear lockedExt on plan9 since we may end up re-using | |
// this thread. | |
mp.lockedExt = 0 | |
} | |
} | |
} |
# 3.10 retake
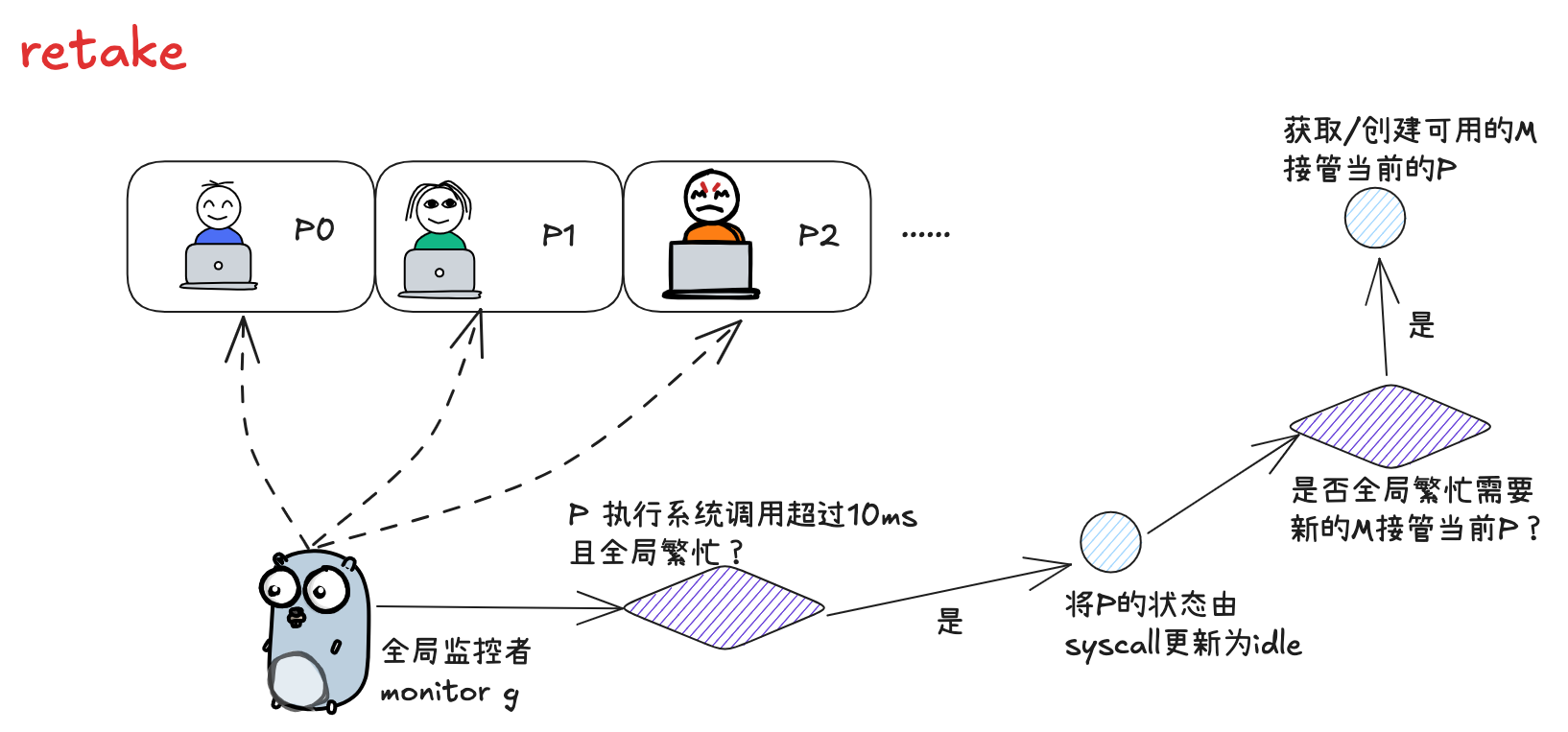
抢占调度的执行者不是 g0,而是一个全局的 monitor g,代码位于 runtime/proc.go
func retake(now int64) uint32 { | |
n := 0 | |
// 加锁后,遍历全局的 p 队列,寻找需要抢占的目标 | |
lock(&allpLock) | |
for i := 0; i < len(allp); i++ { | |
pp := allp[i] | |
if pp == nil { | |
// This can happen if procresize has grown | |
// allp but not yet created new Ps. | |
continue | |
} | |
pd := &pp.sysmontick | |
s := pp.status | |
sysretake := false | |
if s == _Prunning || s == _Psyscall { | |
// Preempt G if it's running on the same schedtick for | |
// too long. This could be from a single long-running | |
// goroutine or a sequence of goroutines run via | |
// runnext, which share a single schedtick time slice. | |
t := int64(pp.schedtick) | |
if int64(pd.schedtick) != t { | |
pd.schedtick = uint32(t) | |
pd.schedwhen = now | |
} else if pd.schedwhen+forcePreemptNS <= now { | |
preemptone(pp) | |
// In case of syscall, preemptone() doesn't | |
// work, because there is no M wired to P. | |
sysretake = true | |
} | |
} | |
// 让若某个 p 同时满足下述条件,则会进行抢占调度: | |
// 1. 执行系统调用超过 10ms | |
// 2. p 本地队列由等待执行的 g | |
// 3. 当前没有空闲的 p 和 m | |
if s == _Psyscall { | |
// Retake P from syscall if it's there for more than 1 sysmon tick (at least 20us). | |
t := int64(pp.syscalltick) | |
if !sysretake && int64(pd.syscalltick) != t { | |
pd.syscalltick = uint32(t) | |
pd.syscallwhen = now | |
continue | |
} | |
// On the one hand we don't want to retake Ps if there is no other work to do, | |
// but on the other hand we want to retake them eventually | |
// because they can prevent the sysmon thread from deep sleep. | |
if runqempty(pp) && sched.nmspinning.Load()+sched.npidle.Load() > 0 && pd.syscallwhen+10*1000*1000 > now { | |
continue | |
} | |
// Drop allpLock so we can take sched.lock. | |
unlock(&allpLock) | |
// Need to decrement number of idle locked M's | |
// (pretending that one more is running) before the CAS. | |
// Otherwise the M from which we retake can exit the syscall, | |
// increment nmidle and report deadlock. | |
incidlelocked(-1) | |
trace := traceAcquire() | |
// 抢占调度的步骤是,先将当前 p 的状态更新为 idle,然后进入 handoffp,判断是否需要为 p 寻找接管的 m(因为其原本绑定的 m 正在执行系统调用) | |
if atomic.Cas(&pp.status, s, _Pidle) { | |
if trace.ok() { | |
trace.ProcSteal(pp, false) | |
traceRelease(trace) | |
} | |
n++ | |
pp.syscalltick++ | |
handoffp(pp) | |
} else if trace.ok() { | |
traceRelease(trace) | |
} | |
incidlelocked(1) | |
lock(&allpLock) | |
} | |
} | |
unlock(&allpLock) | |
return uint32(n) | |
} |
当以下条件满足其一时,则需要 p 获取新的 m:
- 当前 p 本地队列还有待执行的 g
- 全局繁忙(没有空闲的 p 和 m,全局 g 队列为空)
- 需要处理网络 socket 请求处理
func handoffp(pp *p) { | |
// handoffp must start an M in any situation where | |
// findrunnable would return a G to run on pp. | |
// if it has local work, start it straight away | |
if !runqempty(pp) || sched.runqsize != 0 { | |
startm(pp, false, false) | |
return | |
} | |
// if there's trace work to do, start it straight away | |
if (traceEnabled() || traceShuttingDown()) && traceReaderAvailable() != nil { | |
startm(pp, false, false) | |
return | |
} | |
// if it has GC work, start it straight away | |
if gcBlackenEnabled != 0 && gcMarkWorkAvailable(pp) { | |
startm(pp, false, false) | |
return | |
} | |
// no local work, check that there are no spinning/idle M's, | |
// otherwise our help is not required | |
if sched.nmspinning.Load()+sched.npidle.Load() == 0 && sched.nmspinning.CompareAndSwap(0, 1) { // TODO: fast atomic | |
sched.needspinning.Store(0) | |
startm(pp, true, false) | |
return | |
} | |
lock(&sched.lock) | |
if sched.gcwaiting.Load() { | |
pp.status = _Pgcstop | |
pp.gcStopTime = nanotime() | |
sched.stopwait-- | |
if sched.stopwait == 0 { | |
notewakeup(&sched.stopnote) | |
} | |
unlock(&sched.lock) | |
return | |
} | |
if pp.runSafePointFn != 0 && atomic.Cas(&pp.runSafePointFn, 1, 0) { | |
sched.safePointFn(pp) | |
sched.safePointWait-- | |
if sched.safePointWait == 0 { | |
notewakeup(&sched.safePointNote) | |
} | |
} | |
if sched.runqsize != 0 { | |
unlock(&sched.lock) | |
startm(pp, false, false) | |
return | |
} | |
// If this is the last running P and nobody is polling network, | |
// need to wakeup another M to poll network. | |
if sched.npidle.Load() == gomaxprocs-1 && sched.lastpoll.Load() != 0 { | |
unlock(&sched.lock) | |
startm(pp, false, false) | |
return | |
} | |
// The scheduler lock cannot be held when calling wakeNetPoller below | |
// because wakeNetPoller may call wakep which may call startm. | |
when := pp.timers.wakeTime() | |
pidleput(pp, 0) | |
unlock(&sched.lock) | |
if when != 0 { | |
wakeNetPoller(when) | |
} | |
} |
获取 m 时,会先尝试获取已有的空闲 m,若不存在,则会创建一个新的 m
func startm(pp *p, spinning, lockheld bool) { | |
mp := acquirem() | |
if !lockheld { | |
lock(&sched.lock) | |
} | |
if pp == nil { | |
if spinning { | |
// TODO(prattmic): All remaining calls to this function | |
// with _p_ == nil could be cleaned up to find a P | |
// before calling startm. | |
throw("startm: P required for spinning=true") | |
} | |
pp, _ = pidleget(0) | |
if pp == nil { | |
if !lockheld { | |
unlock(&sched.lock) | |
} | |
releasem(mp) | |
return | |
} | |
} | |
nmp := mget() | |
if nmp == nil { | |
id := mReserveID() | |
unlock(&sched.lock) | |
var fn func() | |
if spinning { | |
// The caller incremented nmspinning, so set m.spinning in the new M. | |
fn = mspinning | |
} | |
newm(fn, pp, id) | |
if lockheld { | |
lock(&sched.lock) | |
} | |
// Ownership transfer of pp committed by start in newm. | |
// Preemption is now safe. | |
releasem(mp) | |
return | |
} | |
if !lockheld { | |
unlock(&sched.lock) | |
} | |
if nmp.spinning { | |
throw("startm: m is spinning") | |
} | |
if nmp.nextp != 0 { | |
throw("startm: m has p") | |
} | |
if spinning && !runqempty(pp) { | |
throw("startm: p has runnable gs") | |
} | |
// The caller incremented nmspinning, so set m.spinning in the new M. | |
nmp.spinning = spinning | |
nmp.nextp.set(pp) | |
notewakeup(&nmp.park) | |
// Ownership transfer of pp committed by wakeup. Preemption is now | |
// safe. | |
releasem(mp) | |
} |
# 3.11 reentersyscall 和 exitsyscall
在 m 需要执行系统调用前,会先执行位于 runtime/proc.go 的 reentersyscall 的方法:
此时执行权位于 m 的 g0 手中
func reentersyscall(pc, sp, bp uintptr) { | |
trace := traceAcquire() | |
gp := getg() | |
// Disable preemption because during this function g is in Gsyscall status, | |
// but can have inconsistent g->sched, do not let GC observe it. | |
gp.m.locks++ | |
// Entersyscall must not call any function that might split/grow the stack. | |
// (See details in comment above.) | |
// Catch calls that might, by replacing the stack guard with something that | |
// will trip any stack check and leaving a flag to tell newstack to die. | |
gp.stackguard0 = stackPreempt | |
gp.throwsplit = true | |
// Leave SP around for GC and traceback. | |
// 保存当前 g 的执行环境 | |
save(pc, sp, bp) | |
gp.syscallsp = sp | |
gp.syscallpc = pc | |
gp.syscallbp = bp | |
// 将 g 的状态更新为 syscall | |
casgstatus(gp, _Grunning, _Gsyscall) | |
if staticLockRanking { | |
// When doing static lock ranking casgstatus can call | |
// systemstack which clobbers g.sched. | |
save(pc, sp, bp) | |
} | |
if gp.syscallsp < gp.stack.lo || gp.stack.hi < gp.syscallsp { | |
systemstack(func() { | |
print("entersyscall inconsistent sp ", hex(gp.syscallsp), " [", hex(gp.stack.lo), ",", hex(gp.stack.hi), "]\n") | |
throw("entersyscall") | |
}) | |
} | |
if gp.syscallbp != 0 && gp.syscallbp < gp.stack.lo || gp.stack.hi < gp.syscallbp { | |
systemstack(func() { | |
print("entersyscall inconsistent bp ", hex(gp.syscallbp), " [", hex(gp.stack.lo), ",", hex(gp.stack.hi), "]\n") | |
throw("entersyscall") | |
}) | |
} | |
if trace.ok() { | |
systemstack(func() { | |
trace.GoSysCall() | |
traceRelease(trace) | |
}) | |
// systemstack itself clobbers g.sched.{pc,sp} and we might | |
// need them later when the G is genuinely blocked in a | |
// syscall | |
save(pc, sp, bp) | |
} | |
if sched.sysmonwait.Load() { | |
systemstack(entersyscall_sysmon) | |
save(pc, sp, bp) | |
} | |
if gp.m.p.ptr().runSafePointFn != 0 { | |
// runSafePointFn may stack split if run on this stack | |
systemstack(runSafePointFn) | |
save(pc, sp, bp) | |
} | |
gp.m.syscalltick = gp.m.p.ptr().syscalltick | |
// 解除 p 和 当前 m 之间的绑定,因为 m 即将进入系统调用导致短暂不可用 | |
pp := gp.m.p.ptr() | |
pp.m = 0 | |
// 将 p 添加到 当前 m 的 oldP 容器当中,后续 m 恢复后,会优先寻找旧的 p 重新建立绑定关系. | |
gp.m.oldp.set(pp) | |
gp.m.p = 0 | |
// 将 p 的状态更新为 syscall | |
atomic.Store(&pp.status, _Psyscall) | |
if sched.gcwaiting.Load() { | |
systemstack(entersyscall_gcwait) | |
save(pc, sp, bp) | |
} | |
gp.m.locks-- | |
} |
当 m 完成了内核态的系统调用之后,此时会步入位于 runtime/proc.go 的 exitsyscall 函数中,尝试寻找 p 重新开始运作:
func exitsyscall() { | |
gp := getg() | |
gp.m.locks++ // see comment in entersyscall | |
if getcallersp() > gp.syscallsp { | |
throw("exitsyscall: syscall frame is no longer valid") | |
} | |
gp.waitsince = 0 | |
oldp := gp.m.oldp.ptr() | |
gp.m.oldp = 0 | |
if exitsyscallfast(oldp) { | |
// When exitsyscallfast returns success, we have a P so can now use | |
// write barriers | |
if goroutineProfile.active { | |
// Make sure that gp has had its stack written out to the goroutine | |
// profile, exactly as it was when the goroutine profiler first | |
// stopped the world. | |
systemstack(func() { | |
tryRecordGoroutineProfileWB(gp) | |
}) | |
} | |
trace := traceAcquire() | |
if trace.ok() { | |
lostP := oldp != gp.m.p.ptr() || gp.m.syscalltick != gp.m.p.ptr().syscalltick | |
systemstack(func() { | |
// Write out syscall exit eagerly. | |
// | |
// It's important that we write this *after* we know whether we | |
// lost our P or not (determined by exitsyscallfast). | |
trace.GoSysExit(lostP) | |
if lostP { | |
// We lost the P at some point, even though we got it back here. | |
// Trace that we're starting again, because there was a traceGoSysBlock | |
// call somewhere in exitsyscallfast (indicating that this goroutine | |
// had blocked) and we're about to start running again. | |
trace.GoStart() | |
} | |
}) | |
} | |
// There's a cpu for us, so we can run. | |
gp.m.p.ptr().syscalltick++ | |
// We need to cas the status and scan before resuming... | |
casgstatus(gp, _Gsyscall, _Grunning) | |
if trace.ok() { | |
traceRelease(trace) | |
} | |
// Garbage collector isn't running (since we are), | |
// so okay to clear syscallsp. | |
gp.syscallsp = 0 | |
gp.m.locks-- | |
if gp.preempt { | |
// restore the preemption request in case we've cleared it in newstack | |
gp.stackguard0 = stackPreempt | |
} else { | |
// otherwise restore the real stackGuard, we've spoiled it in entersyscall/entersyscallblock | |
gp.stackguard0 = gp.stack.lo + stackGuard | |
} | |
gp.throwsplit = false | |
if sched.disable.user && !schedEnabled(gp) { | |
// Scheduling of this goroutine is disabled. | |
Gosched() | |
} | |
return | |
} | |
gp.m.locks-- | |
// Call the scheduler. | |
//old 绑定失败,则调用 mcall 方法切换到 m 的 g0,并执行 exitsyscall0 方法 | |
mcall(exitsyscall0) | |
// Scheduler returned, so we're allowed to run now. | |
// Delete the syscallsp information that we left for | |
// the garbage collector during the system call. | |
// Must wait until now because until gosched returns | |
// we don't know for sure that the garbage collector | |
// is not running. | |
gp.syscallsp = 0 | |
gp.m.p.ptr().syscalltick++ | |
gp.throwsplit = false | |
} |
- 方法执行之初,此时的执行权是普通 g. 倘若此前设置的 oldp 仍然可用,则重新和 oldP 绑定,将当前 g 重新置为 running 状态,然后开始执行后续的用户函数;
_g_ := getg() | |
// ... | |
if exitsyscallfast(oldp) { | |
// ... | |
casgstatus(_g_, _Gsyscall, _Grunning) | |
// ... | |
return | |
} |
- old 绑定失败,则调用 mcall 方法切换到 m 的 g0,并执行 exitsyscall0 方法:
mcall(exitsyscall0) | |
func exitsyscall0(gp *g) { | |
var trace traceLocker | |
traceExitingSyscall() | |
trace = traceAcquire() | |
// 将 g 由系统调用状态切换为可运行态 | |
casgstatus(gp, _Gsyscall, _Grunnable) | |
traceExitedSyscall() | |
if trace.ok() { | |
// Write out syscall exit eagerly. | |
// | |
// It's important that we write this *after* we know whether we | |
// lost our P or not (determined by exitsyscallfast). | |
trace.GoSysExit(true) | |
traceRelease(trace) | |
} | |
// 解绑 g 和 m 的关系 | |
dropg() | |
// 从全局 p 队列获取可用的 p,如果获取到了,则执行 g | |
lock(&sched.lock) | |
var pp *p | |
if schedEnabled(gp) { | |
pp, _ = pidleget(0) | |
} | |
var locked bool | |
如若无 p 可用,则将 g 添加到全局队列,当前 m 陷入沉睡. 直到被唤醒后才会继续发起调度. | |
if pp == nil { | |
globrunqput(gp) | |
locked = gp.lockedm != 0 | |
} else if sched.sysmonwait.Load() { | |
sched.sysmonwait.Store(false) | |
notewakeup(&sched.sysmonnote) | |
} | |
unlock(&sched.lock) | |
if pp != nil { | |
acquirep(pp) | |
execute(gp, false) // Never returns. | |
} | |
if locked { | |
// Wait until another thread schedules gp and so m again. | |
// | |
// N.B. lockedm must be this M, as this g was running on this M | |
// before entersyscall. | |
stoplockedm() | |
execute(gp, false) // Never returns. | |
} | |
stopm() | |
schedule() // Never returns. | |
} |
# 4. 可视化查看 GMP 数据
# 4.1 go tool trace
trace 记录运行时的信息,能提供可视化的 Web 页面
func main() { | |
f, err := os.Create("trace.out") | |
if err != nil { | |
panic(err) | |
} | |
defer f.Close() | |
err = trace.Start(f) | |
if err != nil { | |
panic(err) | |
} | |
defer trace.Stop() | |
fmt.Println("hello gmp") | |
} |
运行程序
$ go run trace.go | |
hello gmp |
生成 trace.out 文件,使用 go tool trace trace.out 查看可视化界面
$ go tool trace trace.out | |
2025/10/16 10:22:33 Preparing trace for viewer... | |
2025/10/16 10:22:33 Splitting trace for viewer... | |
2025/10/16 10:22:33 Opening browser. Trace viewer is listening on http://127.0.0.1:53079 |
可以通过浏览器 http://127.0.0.1:60406 查看可视化界面,点击 View trace 查看可视化的调度流程
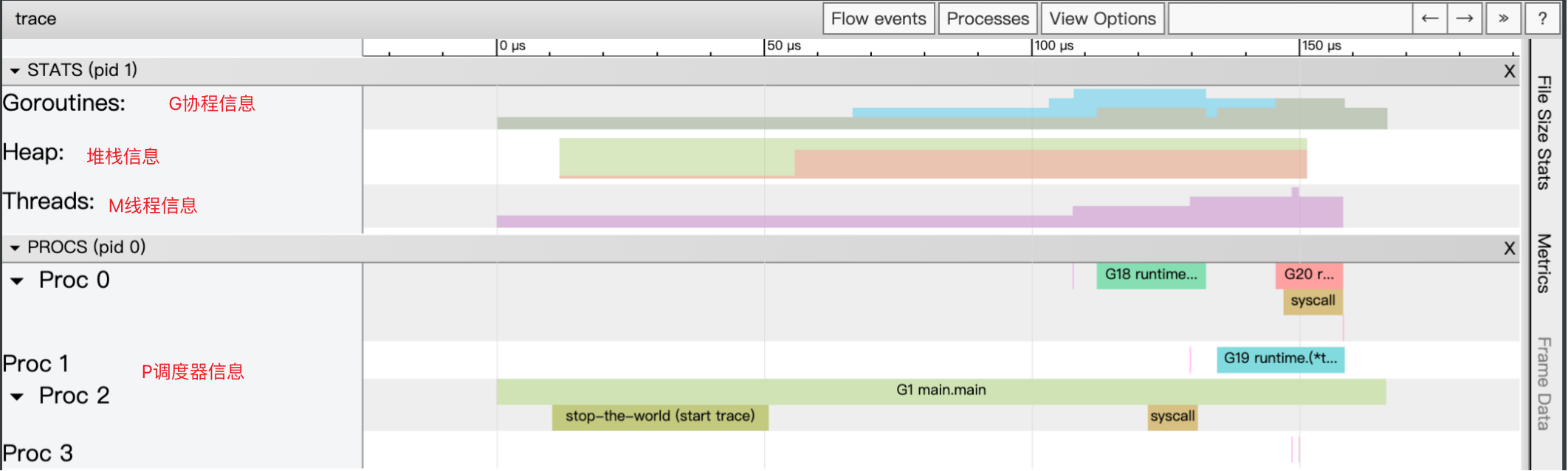
# 4.2 Debug trace
func main() { | |
for i := 0; i < 5; i++ { | |
time.Sleep(time.Second) | |
fmt.Println("hello gmp") | |
} | |
} |
编译
$ go build trace2.go |
通过 Debug 方式运行
$ GODEBUG=schedtrace=1000 ./trace1 | |
SCHED 0ms: gomaxprocs=8 idleprocs=7 threads=2 spinningthreads=0 needspinning=0 idlethreads=0 runqueue=0 [0 0 0 0 0 0 0 0] | |
hello gmp | |
SCHED 1006ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 needspinning=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] | |
hello gmp | |
SCHED 2015ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 needspinning=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] | |
hello gmp | |
SCHED 3025ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 needspinning=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] | |
hello gmp | |
SCHED 4031ms: gomaxprocs=8 idleprocs=8 threads=5 spinningthreads=0 needspinning=0 idlethreads=3 runqueue=0 [0 0 0 0 0 0 0 0] | |
hello gmp |
- SCHED: 调试信息输出标志字符串,代表本行是 goroutine 调度器的输出
- 0ms: 即从程序启动到输出这行日志的时间
- gomaxprocs: P 的数量,本例有 8 个 P,因为默认的 P 的属性和 CPU 核心数量默认一致,也可通过 GOMAXPROCS 来设置
- idleprocs: 处于 idle 数量的 P 的数量;通过 gomaxprocs 和 idleprocs 的差值,可知道执行 go 代码的 P 的数量
- threads: os 线程数量,包含 scheduler 使用的 m 数量,加上 runtime 自用的类似 sysmon 这样的线程
- spinningthreads: 处于自旋状态的 os 线程数量
- needspinning: 需要自旋的 P 的数量
- idlethreads: 没有执行 go 代码的 os 线程数量,包含自旋线程和空闲线程
- runqueue=0: 全局队列中 g 的数量